
This series of blog articles is related to a presentation delivered at GameSoundCon in October 2020. The goal of the presentation was to provide perspective and tools for creators to refine their next project by using object-based audio rendering techniques. These techniques reproduce sound spatialization as close to how we experience sound in nature as possible.
This content has been separated in three parts:
- The first part, covered by this article, exposes audio professionals to the advantages of authoring their upcoming projects using object-based audio, as opposed to channel-based audio, by showing how this approach can yield better outcomes for a plurality of systems and playback endpoints.
- The second part will explain how Wwise version 2021.1 has evolved to provide a comprehensive authoring environment that fully leverages audio objects while enhancing the workflow for all mixing considerations.
- Finally, the third part will share a series of methods, techniques, and tricks that have been employed by sound designers and composers using audio objects for recent projects.
Encoding Spatialization - An Historical Overview
The practice of encoding audio for reproduction has been around for more than a hundred years. For several decades, such encoding was captured in mono which, by design, couldn't provide spatialization (although, some may argue that mono recordings can easily capture a sense of depth, which is a form of spatialization). It was only in the 1970s, with the mass adoption of stereo systems, that reproduction of music carrying spatialization became available to the public. With the general acceptance of the stereo format, sound engineers and music aficionados started mixing for and talking about spatialization and directionality of sound.
Later, in the 1980s, with the widespread adoption of VCRs (Videocassette Recorders) and the ability to rent films on VHS (Video Home System), the industry gathered around the idea of offering the movie theater experience at home… provided that the general public would purchase new sound system setups! That's how the industry evolved from LCRS (Left-Center-Right-Surround), to proper 5.1 speaker configurations offering full dynamic and frequency range, to 7.1, and now, to 7.1.4 with the addition of height channels. 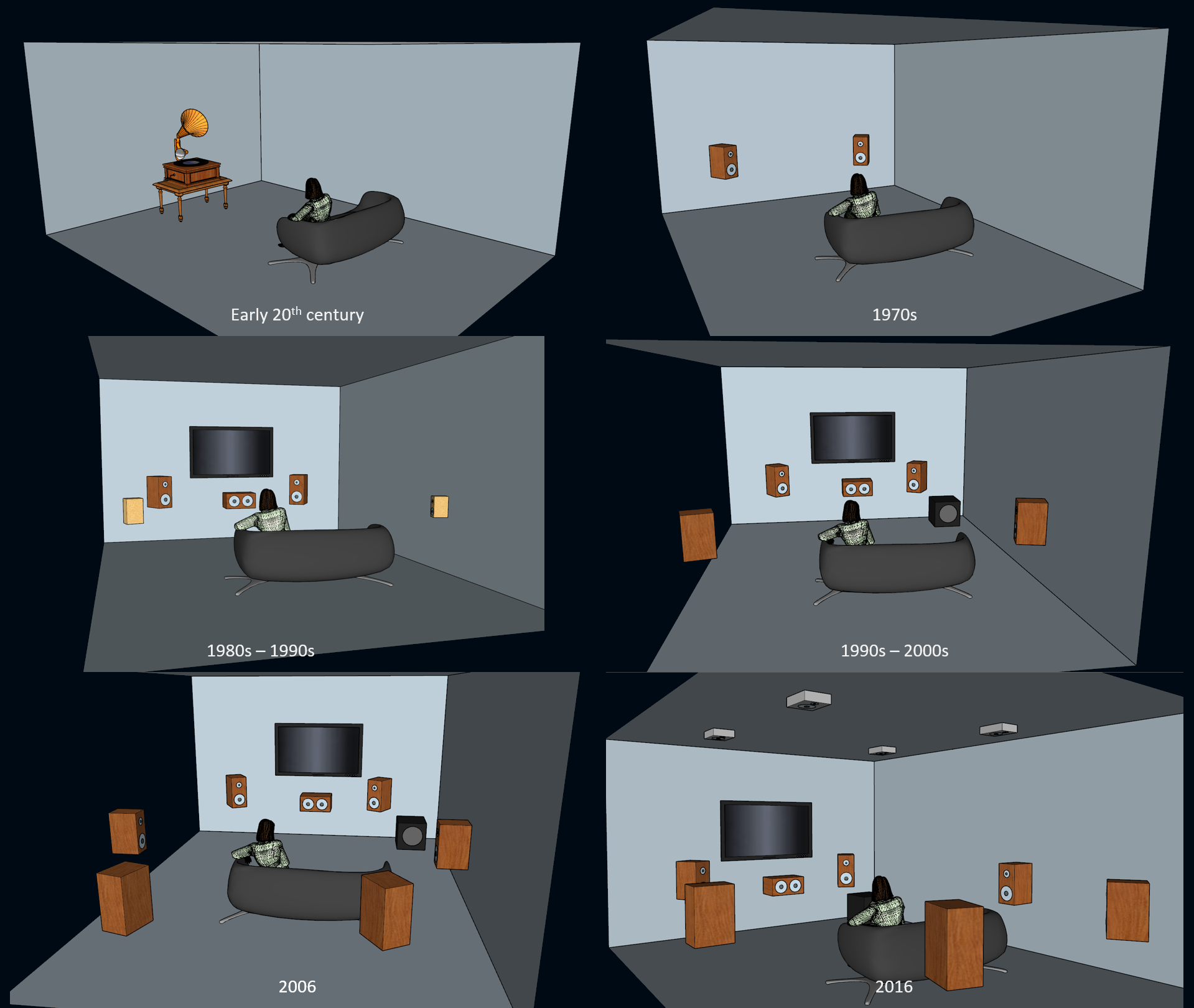
The evolution of the consumer landscape of spatial audio reproduction
That said, over the past decade, the typical lifestyle has shifted toward mobility and the idea of adding more speakers to the living room is making way for the increased use of headphones. The ubiquity of mobile and multiplayer games has certainly contributed to this shift. Looking at speaker vs. headphone sales trends and the anticipated market size for the coming years, there are strong indications that people will continue playing game audio over headphones in the future.
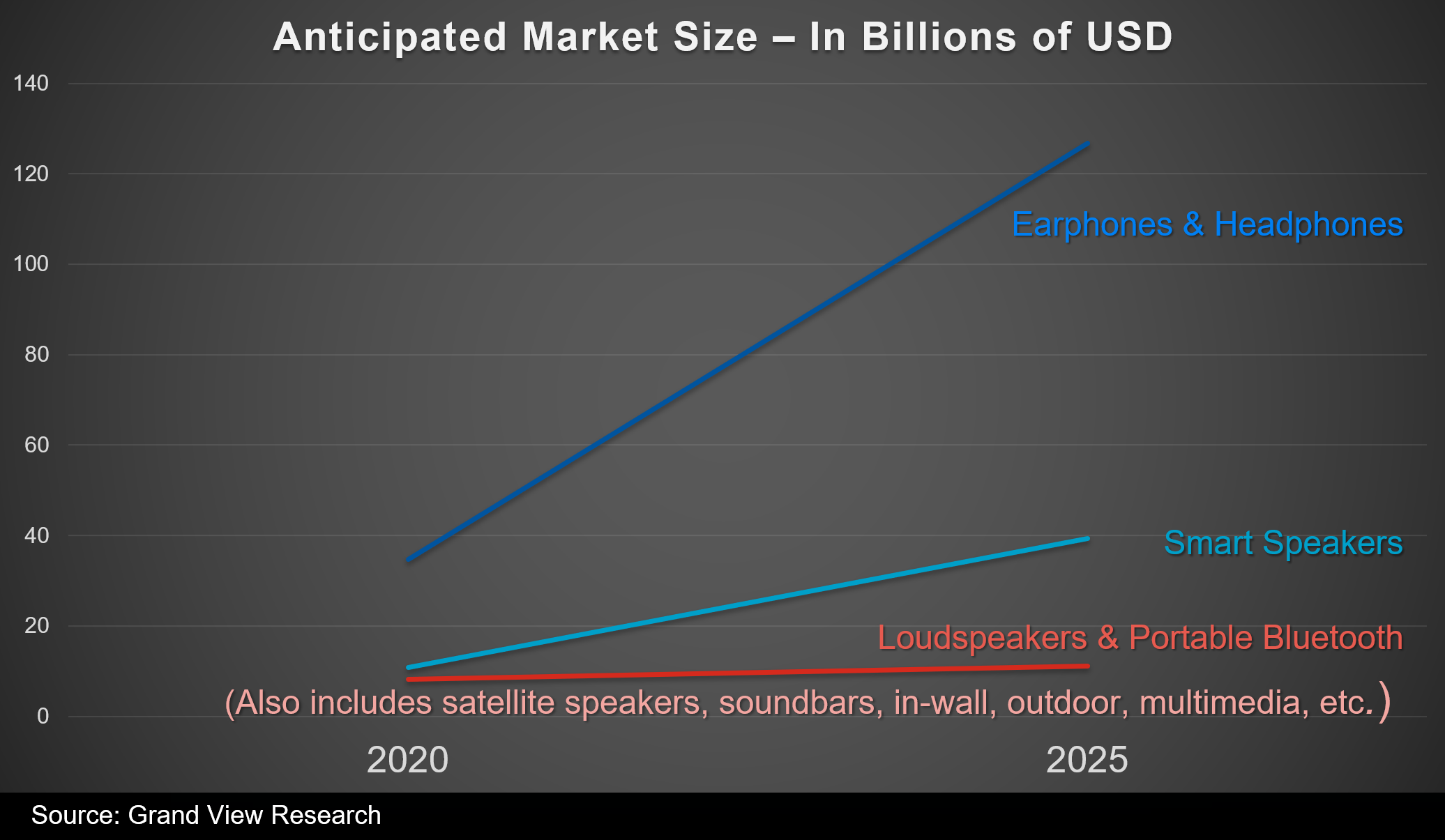
Earphones & Headphones domination over speakers in anticipated sales projection and growth for the next five years
Perceiving Audio in Space
To deliver life-like experiences with synthesized audio over speakers or headphones, two factors should coexist and complement each other:
- Tools and Technology: the audio reproduction technology should simulate as accurately as possible the physics of sound.
- Human Experience: the performance should match our expectations as human beings.
Let’s look at these two factors in more detail.

Technology and our experience as human beings are the two factors at play in our ability to perceive synthesized sound in space as experienced in nature.
Reproducing Directionality
HRTF (Head-Related Transfer Function) is typically the best technology available when a high level of precision in sound directionality over headphones is necessary. To reproduce the sound directionality with accuracy, HRTF algorithms leverage the following perceptual cues:
- ITD (Interaural Time Difference): Represents the difference in arrival time for a single sound between two ears. The time difference is not even a millisecond, but it's enough for the brain to pick up directionality.
- IID (Interaural Intensity Difference): Represents the obstruction effect of the head on one of the two ears which creates relative amplitude, timber and phase differences between the ears. This effect is more or less pronounced depending on the signal's frequency.
- Spectral Cues: Represent the different patterns, at the eardrum, of peaks and notches across frequency of the same sound presented from different directions.
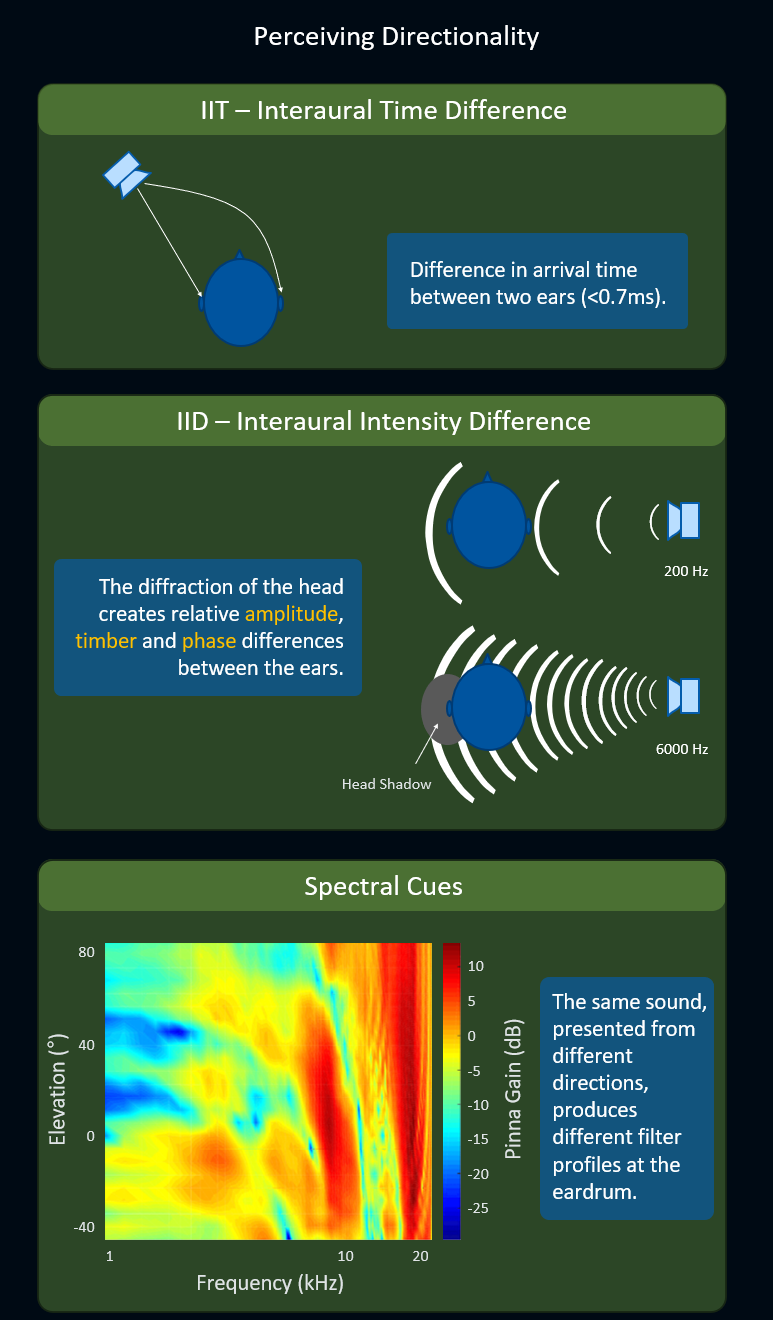
Use of ITD, IID and Spectral Cues techniques to enhance the accuracy of the sounds spatialized around the listener. This article illustrates well how HRTF is measured.
Reproducing Environmental Effects
The other aspects that can be reproduced by technology are environmental effects, such as distance attenuation, dynamic early reflections, late reverberation, sound propagation, diffraction, and obstruction. The more elements from those phenomena are used, the more information the brain receives to better perceive sounds in space. Note that much more could be said about the contribution of environmental effects to 3D spatialization, but this article focuses on the advantages of using audio objects over channel-based audio.
The Human Experience Factor
The other factor affecting our ability to locate audio in space doesn't rely on technology, but on three aspects of our experience as human beings.
The first aspect concerns the "rendering of the source material": if you hear somebody whispering, that person is probably nearby, certainly much closer than if you hear the same sentence shouted very loud, for example.
The second aspect is about "preconception and learned behavior" where, as humans, we expect certain sounds, such as a helicopter or a plane to come from above our head, for example. This is something we learn over time as we grow.
Finally, the third aspect concerns "visual fusion" where our eyes help our ears to precisely locate emitting sounds in 3D space. For example, if you hear a sound coming from outside your field of view, you'll be able to guess that it's somewhere on your left side, but it's only after you have moved your head to find with your eyes the sound emitter that you'll know precisely where that object is located in space.
This section on how the human experience participates in our ability to perceive audio in space has been well detailed by Brian Schmidt in his great lecture “Technology's Impact on Creativity, Case Study: Beyond HRTF” presented at MIGS 2017.
Channel-Based Audio
Now that we have clarified how we perceive sound in space and how technology can reproduce some of the essential cues involved in this perception, let’s have a look at how we have used different channel-based formats over the years to encode directionality and environmental effects on various media, such as vinyl, tapes, and digital, but also with runtime applications, such as Wwise.

With channel-based formats, the directionality and environmental effects are encoded by the application
Relying on channel-based formats to encode spatialization was a convenient solution considering the technology and computing resources available at the time. However, this approach exposes multiple shortcomings when better spatial accuracy is required. Typical weaknesses are elements such as uneven angles between channel positions causing image distortion and amplitude lulls, phase issues with fast moving sounds, and configurations that can only reproduce sound over a plane or hemisphere. This also excludes the reality at the consumer level where speakers may be missing, placed incorrectly, wired out of phase, etc.
It’s worth noting that none of the shortcomings mentioned above apply to Ambisonics even though it’s technically a channel-based format. Ambisonics uses channels to encode a spherical representation of an audio scene, and the more channels are used, the more accurate the audio scene becomes. The following articles provide a good overview of the Ambisonics format, and how it can be used as an intermediate spatial representation.
What is the endpoint?
We use the term endpoint to refer to the system device (e.g., the section in charge of the audio at the operating system level of the platform) that is responsible for the final processing and mixing of the audio to be sent out to headphones or speakers.
At initialization of the game, Wwise is informed of the endpoint’s audio configuration (e.g., 2.0, 5.1, Windows Sonic for Headphones, and PS5 3D Audio.) so it renders its audio in the format expected by the endpoint.
The Advent of Audio Objects
For many years, the gold standard for sound engineers mixing linear or non-linear audio has been to work in a controlled environment and use high quality speakers across the highest number of audio channels available at the time (5.1, 7.1, etc.). This methodology ensured that any fold down to a lesser number of channels would still provide a coherent mix and dialogue intelligibility across the plurality of listening environments at the consumer level. This approach, while functional, lacks spatial precision due to the limitations inherent to encoding spatialization using channel-based formats as pointed out earlier in this article.
A preferable approach to deliver better spatialization to end-users is to delegate the encoding of directionality to the endpoint. The endpoint is in a much better position to know precisely how the end-user is listening to the content, as the configuration has been set by the user, or through the handshake with the rest of the devices in the audio chain (e.g., the receiver, TV, and soundbar). Therefore, the endpoint can use the most appropriate rendering method to deliver the final mix over headphones or speakers.

With the object-based format, the responsibility of encoding directionality is deferred to the endpoint.
To render the best directionality, the endpoint must be provided with a rich set of information by the application, which takes the form of a series of audio objects and their associated metadata. More precisely, an audio object represents the combination of an audio buffer and its accompanying metadata, which is created and modified by the Wwise rendering pipeline prior to being sent to the endpoint. The metadata types attached to objects are generated by Wwise and are related to audio and plug-in information (the blue box in the figure below). This information should not be confused with the type of information carried by game objects from the game engine (the green box).

Types of metadata provided with audio objects (the blue box) vs. the information provided by game objects (the green box).
Conclusion
This article exposes the benefits of adopting object-based audio with regards to the quality and precision of the spatialization as it is executed by the end-user’s actual device, which may be unique to each user. This new approach, while providing much more natural sound spatialization, enables additional considerations at authoring time. These will be discussed in the next article of this three-part series.

Comments