
Bienvenue à nouveau dans notre série d'articles sur le plugiciel Impacter. Dans les deux articles précédents, nous avons essentiellement parlé des aspects concernant les paramètres physiques du plugiciel et comment ils peuvent bien s'intégrer au système de physique de votre jeu. Dans cet article, nous allons aborder l'autre facette d'Impacter : sa capacité de synthèse croisée.
Comme nous l'avons vu brièvement dans le premier article sur Impacter, la possibilité de mélanger et d'associer les composants « Impact » (impact) et « Body » (corps) de différents sons peut être utilisée pour créer des variations originales au sein d'un groupe de sons. Nous avons même implémenté un option de lecture aléatoire dans le plugiciel afin de permettre aux concepteurs-ices d'utiliser facilement ces variations.
Pour rappel : les variations issues de la synthèse croisée sont produites en prenant les composants « Body » (sinusoïdes & banques de filtres) et « Impact » (excitateur) du module de synthèse de différents sons.
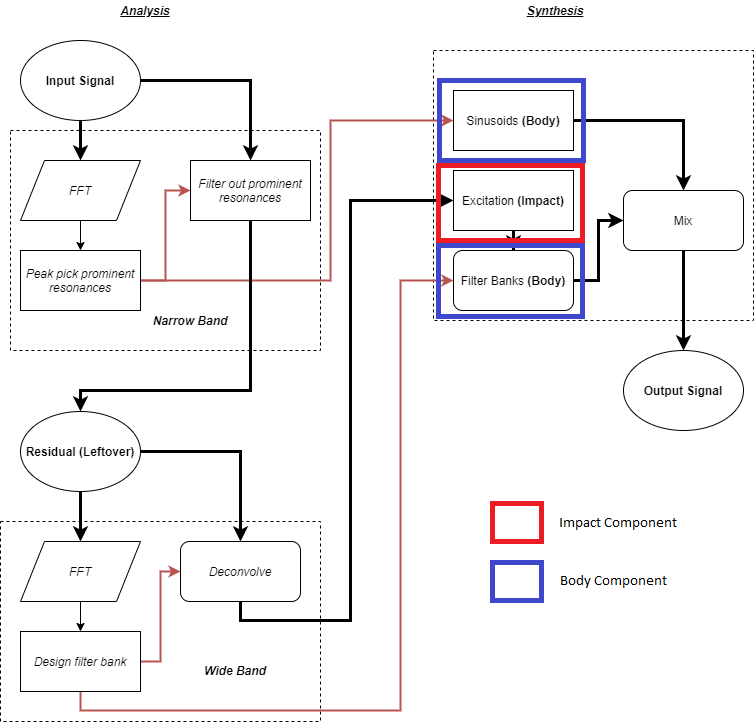
La synthèse croisée, cependant, peut regrouper beaucoup de choses différentes, et il est utile de préciser les types de variations auxquels on peut s'attendre concernant la synthèse croisée particulière d'Impacter. Nous aimerions vous montrer à quel point les variations obtenues avec Impacter peuvent être efficaces et cohérentes ; et qu'elles permettent d'éviter toute redondance sonore, tout en restant représentatives des sons originaux de manière significative. Nous voudrions également garantir aux concepteurs-ices qu'il ne devrait pas y avoir de répétitions de sons pouvant causer une perte de la sensation d'immersion, soit parce qu'ils seraient trop similaires, soit trop différents. Mais comme nous allons le voir, il n'est pas aussi simple d'arriver à une description aussi transparente de la synthèse croisée d'Impacter.
Regarder les variations, écouter les variations
Impacter permet d'effectuer une synthèse croisée en combinant deux sons depuis n'importe quels fichiers précédemment chargés dans le plugiciel. 12 fichiers audio, par exemple, permettent d'obtenir jusqu'à 144 combinaisons (l'utilisateur peut volontairement exclure certains composants d'impact et de corps via la fenêtre Source Editor). Il est bien sûr évident qu'à l'écoute, voire même en jugeant du regard, il est trop difficile de discerner une quelconque différence significative entre 144 sons d'impact.
Par exemple :

Et, pour ce que ça vaut, il serait clairement insensé d'écouter tous les sons dans l'ordre, et de se rappeler à quoi ressemblait le son n.11 une fois arrivé au son n.87....
Alors, que pouvons-nous faire pour examiner efficacement une telle quantité écrasante de sons ?
Réduction de la dimensionnalité
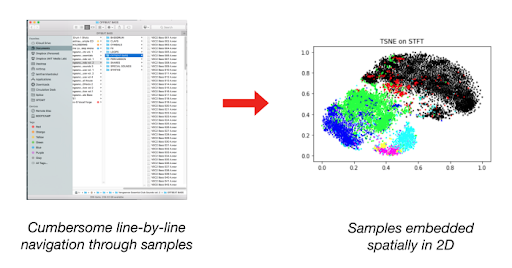
En termes plus généraux d'analyse audio, la technique de réduction de la dimensionnalité nous permet de projeter une grande collection de sons sur un plan à observer en 2D. Le blog de Lamtharn « Hanoi » Hantrakul concernant Klustr et l'outil qui l'accompagne [1], ainsi que le visualiseur « Audio t-SNE » de ml4a (Machine Learning for Artists toolkit) [2] sont deux excellents exemples de ce à quoi ressemble la réduction de la dimensionnalité en audio.
Comparaison des caractéristiques latentes des sons d'impact
Il existe de nombreuses façons de « comparer » des sons dans un espace 2D. Les sons d'impact possèdent un ensemble intuitif de caractéristiques latentes : leurs caractéristiques physiques (dur, mou, rebond, frappe), ou le type d'objet ou de surface impacté (verre, sable, bois). Nous ne pouvons pas définir explicitement (en termes mathématiques) quelles sont les caractéristiques latentes d'un son que nous recherchons, mais nous pouvons essayer d'extraire diverses caractéristiques audio d'un son pour le comparer.
Lorsque l'on travaille avec de l'audio, la comparaison du signal brut dans le domaine temporel, comme dans l'exemple ci-dessus, n'est souvent pas la meilleure manière de comparer différents sons. Heureusement, il existe un large éventail de techniques d'analyse audio permettant de transformer des sons en une forme plus comparable. Comme nous le verrons plus tard, le choix de la technique d'analyse audio affecte directement les tracés résultants de la réduction de la dimensionnalité.
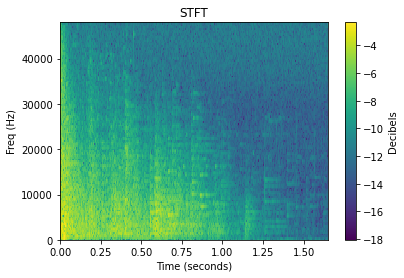
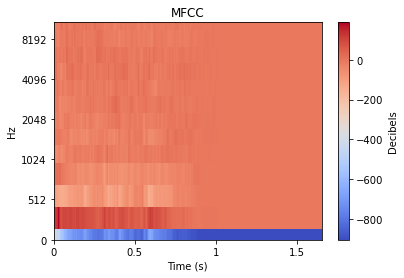
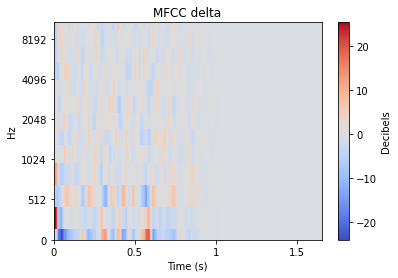
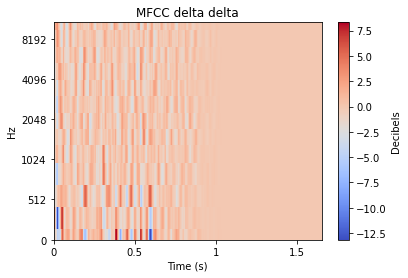
Chacune de ces transformations peut être approfondie de manière très poussée, mais pour le bien de cet article, nous nous contenterons de fournir un exemple visuel de la transformation appliquée à un son de type impact. Beaucoup de ces transformations étendent souvent un signal audio 1D en 2D, et le niveau de chaque valeur est donc représenté par une couleur.
CARACTÉRISTIQUES AUDIO |
|
 |
 |
 |
 |
Puisque, au bout du compte, la réduction de la dimensionnalité fournit une comparaison visuelle des sons, il est possible de considérer de manière intuitive la façon dont la STFT (ou TFCT, Transformée de Fourier à Court Terme) de deux sons pourrait différer, par rapport à la façon dont leurs MFCC (Mel-Frequency Cepstral Coefficients ou coefficients cepstraux) pourraient différer. Ce n'est pas aussi explicite que de comparer, par exemple, les aspects latents des sons suivants : sons de « tambour » par rapport à des sons de « trombone » ou de « gravier ». Cependant, les caractéristiques audio peuvent malgré tout finir par créer une carte 2D qui se rapproche assez bien des différences latentes entre les sons.
Ce que fait la réduction de la dimensionnalité
Maintenant que nous disposons de caractéristiques audio, la réduction de la dimensionnalité nous permet de « réduire » la liste des nombres associés à chaque son dans une collection donnée (comme dans la figure ci-dessous) à une collection de listes de 2 nombres, ou paires, pouvant correspondre aisément aux coordonnées X-Y d'un plan bidimensionnel. Cependant, il est important que la proximité ou la distance entre les sons de ce plan 2D reflète des similarités ou des différences significatives dans le son. En un sens, c'est une manière de simplifier la comparaison visuelle entre tous les sons (ou caractéristiques) que nous avons examinés ci-dessus.

Exemple d'une collection de sons d'une durée de 2 secondes chacun à une fréquence d'échantillonnage de 48kHz, qui seraient donc de 96000 échantillons chacun, réduite à une collection de coordonnées 2D
En résumé, l'ensemble du pipeline de « réduction de la dimensionnalité » ressemble à quelque chose comme ceci :
| SON | EXTRACTION DES CARACTÉRISTIQUES | RÉDUCTION DE LA DIMENSIONNALITÉ | PLAN 2D |
|
|
|
 |
Visualiser la synthèse croisée d'Impacter
Pour obtenir un résultat convaincant de réduction de la dimensionnalité, il est nécessaire de travailler avec un groupe de sons suffisamment grand. Heureusement, nous avons sous la main un projet Wwise avec beaucoup de variations d'Impacter à analyser : la Démo Unreal d'Impacter ! (Lire l'article ici !)
Le projet de démonstration d'Impacter comporte 289 sons répartis sur plusieurs instances Impacter, ce qui aboutit à un total de 2295 variations possibles à examiner. Pour nos expérimentations, nous avons pu faire une exécution offline de notre algorithme d'Impacter pour générer toutes ces variations, puis nous avons pu comparer les résultats obtenus en essayant différentes méthodes d'extraction de caractéristiques audio en entrée, ainsi que différents algorithmes de réduction de la dimensionnalité pour générer des tracés.
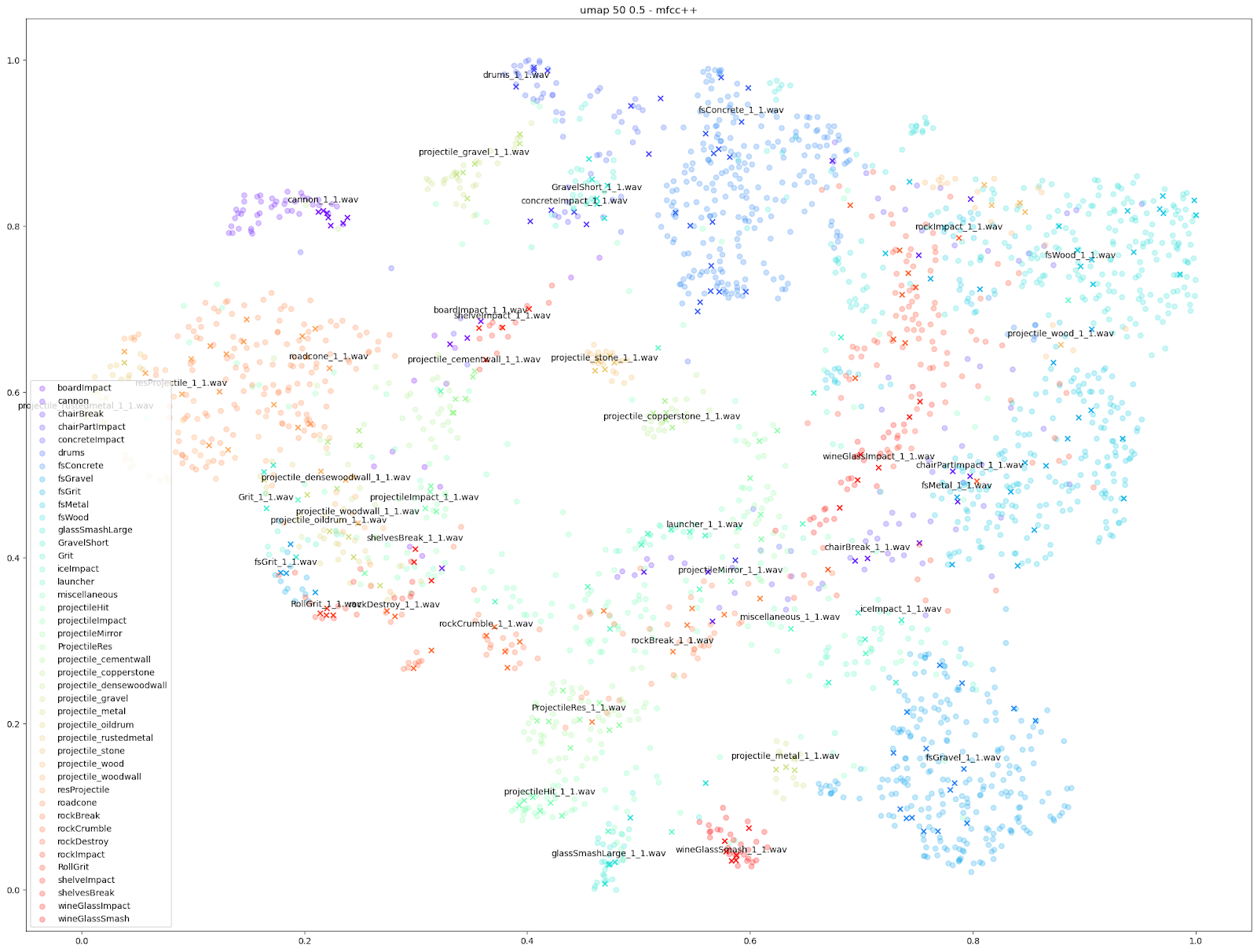
Puisque nous savons quels sons proviennent de quelle instance d'Impacter, nous sommes en mesure d'attribuer une couleur à chaque SFX d'Impacter, et différentes formes pour distinguer les sons originaux des variations. Dans les cas ci-dessous, nous utilisons un « X » pour désigner les sons originaux utilisés en entrée, et un cercle pour les variations produites par Impacter. Le code couleur permet de mettre en avant l'homogénéité des variations : elles sont à proximité de leur original de même couleur ; et montrent également que les variations ne sont pas redondantes : elles ne sont pas superposées les unes aux autres.
Nous avons essayé plusieurs caractéristiques audio et algorithmes de réduction de la dimensionnalité différents, et leurs résultats généraux se trouvent en bas de cet article, mais voici nos résultats préférés :
Nous pouvons constater, dans tous les cas, un certain équilibre des différences entre les originaux et les variations avec chaque instance d'Impacter (chaque couleur). Impacter ne se contente pas non plus de générer des sons au hasard : les sons de mêmes couleurs finissent toujours par se regrouper les uns près des autres, ce qui indique une certaine cohérence entre les variations et leurs originaux.
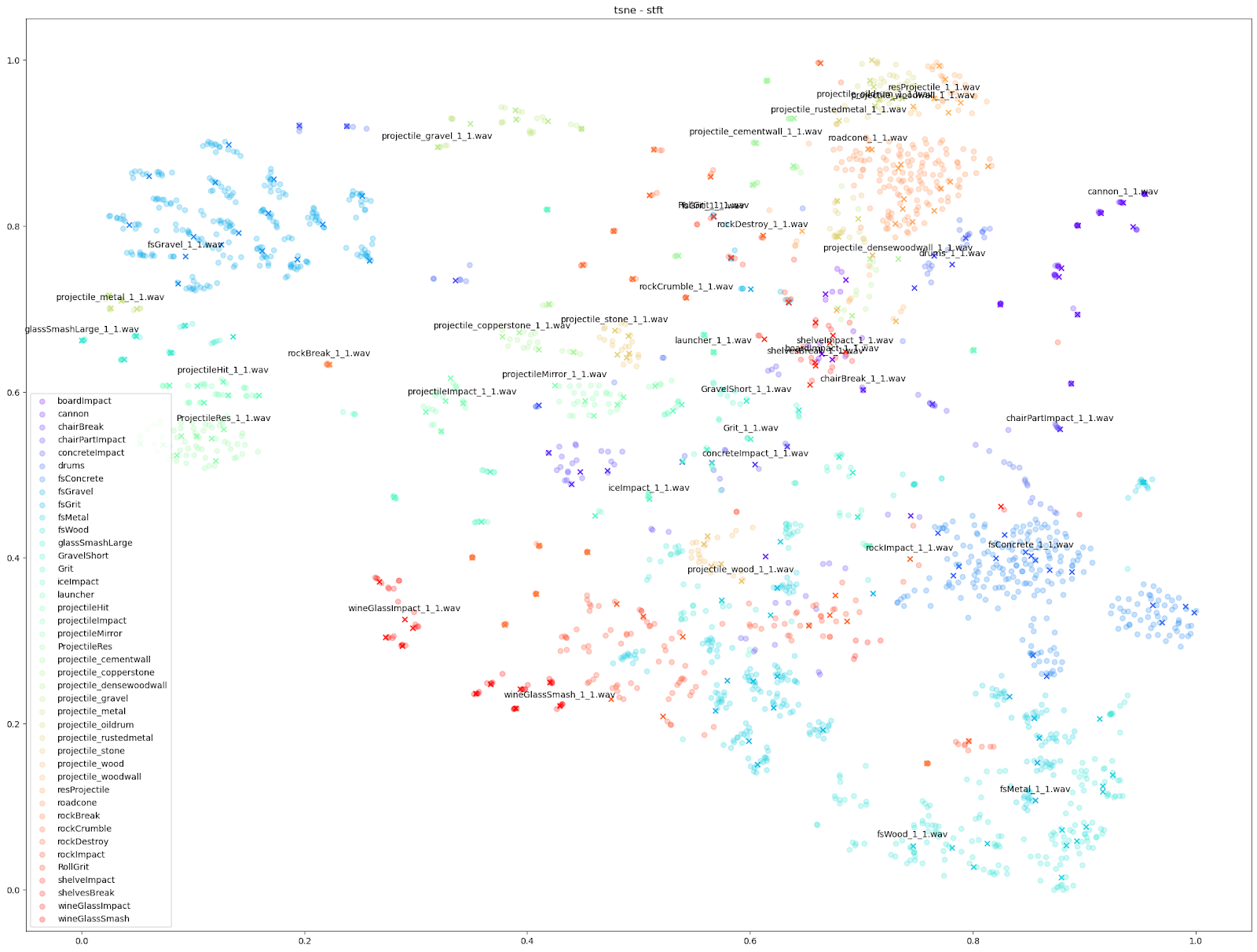
En examinant de près le plan de t-SNE pour les caractéristiques STFT, nous pouvons voir les différents types de variations obtenus parmi les STFT de chaque son d'Impacter. Les résultats optimaux en bas à droite - les sons de béton (« fsConcrete »), de bois (« fsWood ») et de métal (« fsMetal ») - montrent une répartition presque uniforme des variations sonores autour des sons originaux.
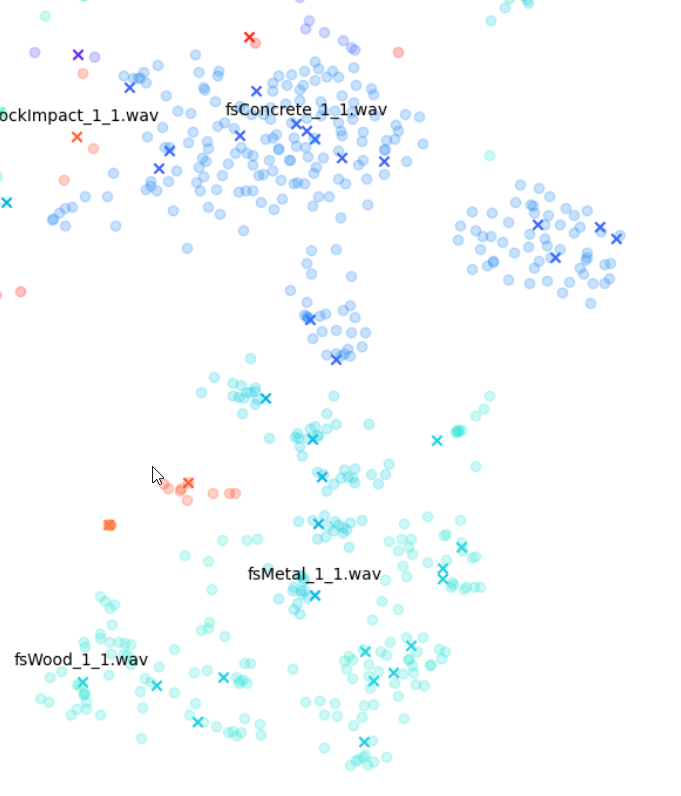
En revanche, les sons de verres à vin (« wineGlassImpact » et « wineGlassSmash ») ou de canons (« cannon »), qui ont des points presque alignés sur les X, montrent que les STFT de chaque variation sont beaucoup plus similaires à leurs originaux.
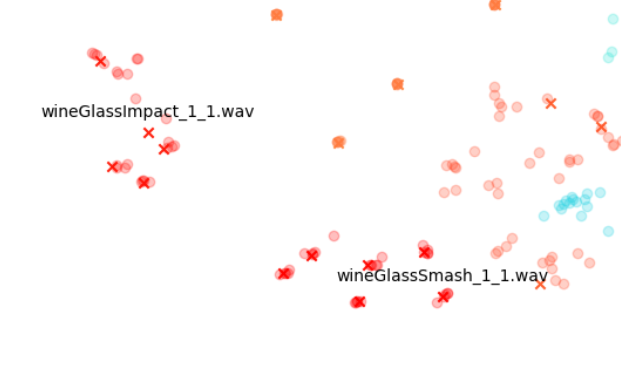
En comparaison, les sons de gravier en haut à gauche (« fsGravel ») se situent dans une sorte d'entre-deux, où l'on peut voir des variations évidentes, mais les variations que l'on trouve autour de chaque fichier original sont particulièrement distinctes des autres clusters « original + variations correspondantes ».
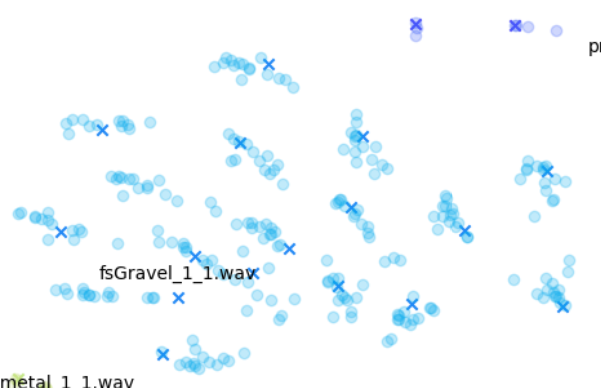
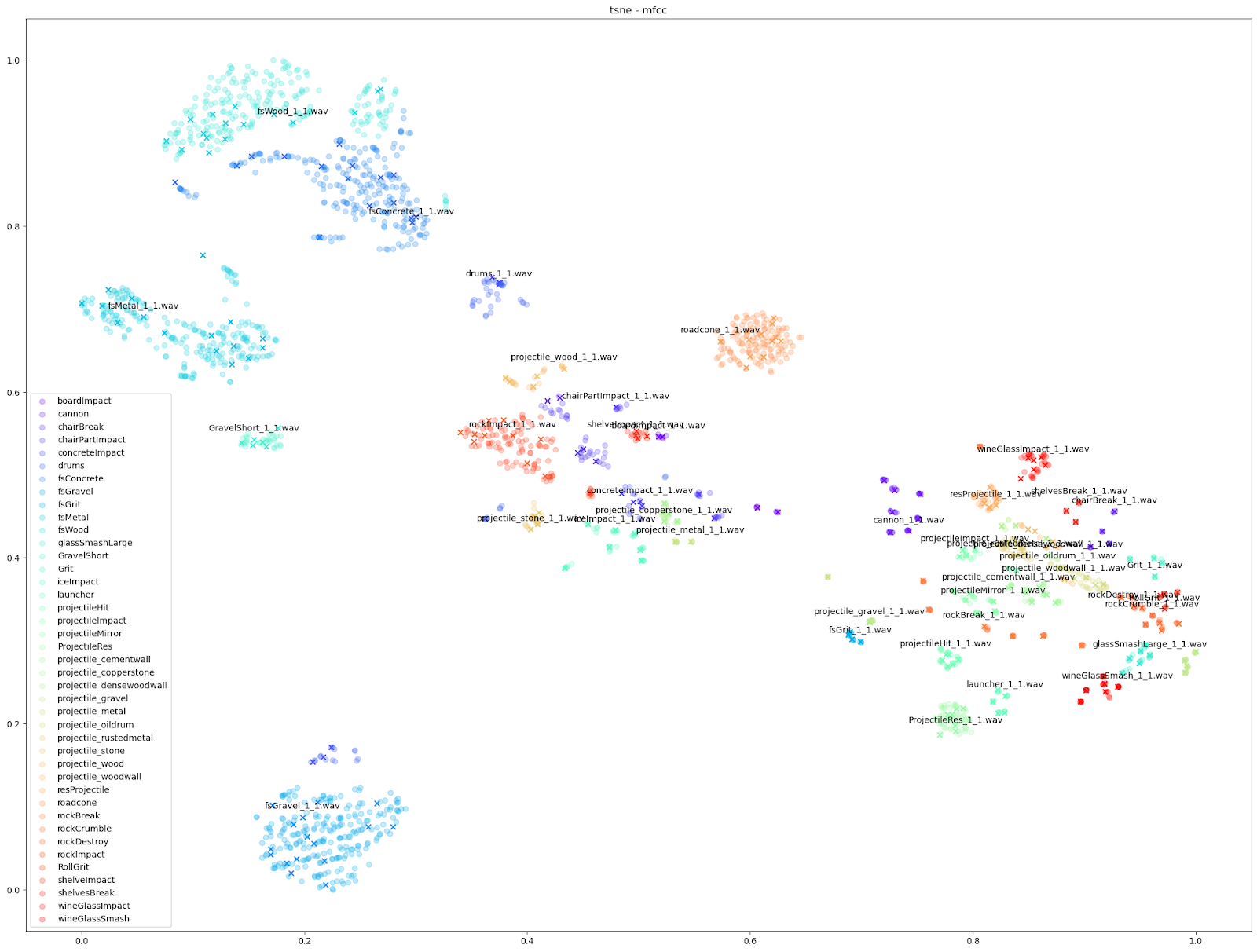
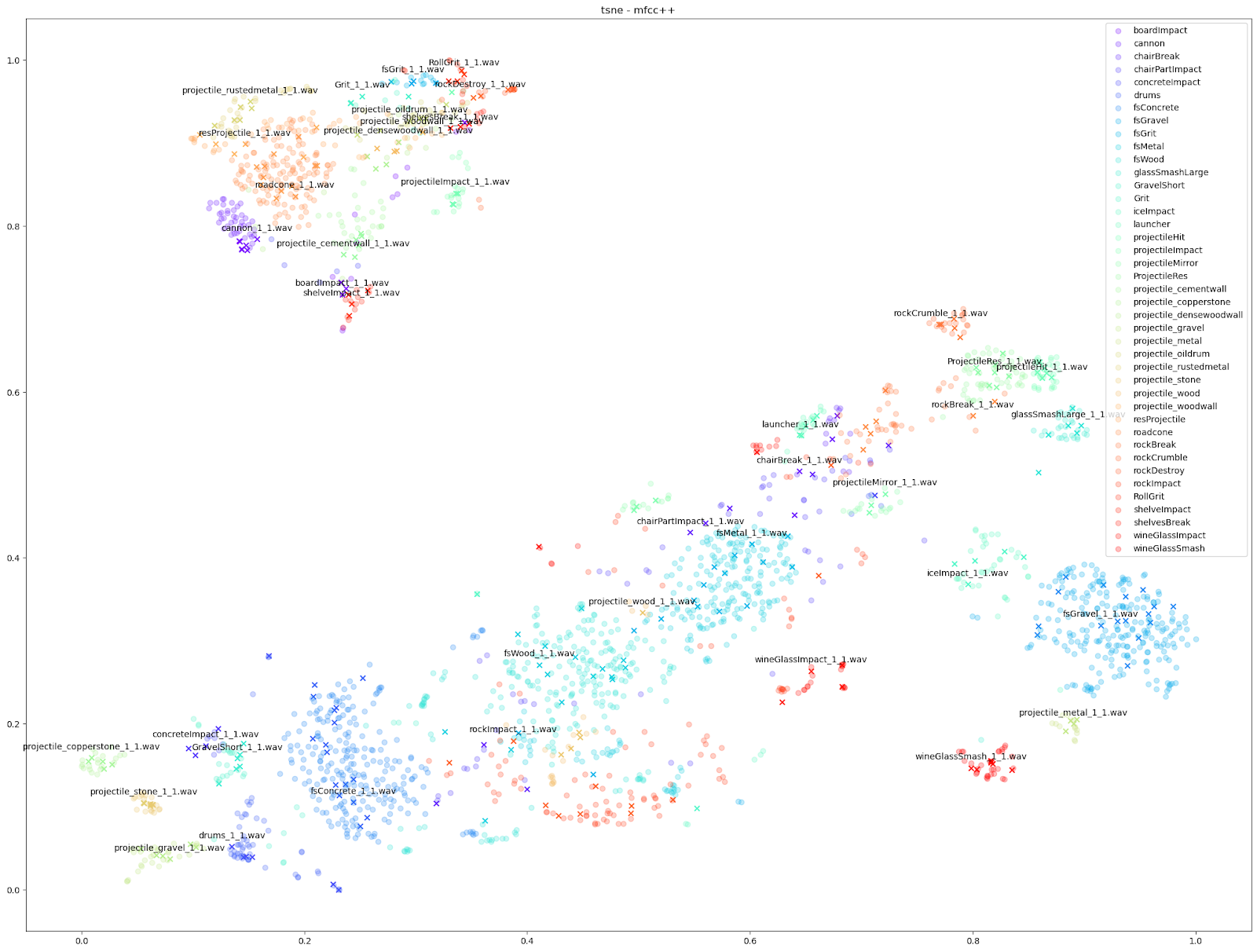
D'autres caractéristiques audio peuvent cependant souligner des différences plus petites, comme les tracés « mfcc++ ». L'inclusion des premier et deuxième deltas (la partie « ++ » de « mfcc++ ») [3] augmente la dispersion entre des clusters qui seraient plus regroupés dans un plan STFT, comme les clusters de verre à vin.
.png)
Nous disposons maintenant d'un graphique qui met en valeur les différences entre les sons dans l'espace 2D de telle sorte qu'il nous permet de voir toutes les variations en même temps, et même de zoomer sur des sons particuliers pour voir comment ils varient localement. Cela est bien beau, mais cela fournit également une anecdote utile sur le fonctionnement d'Impacter.
Impacter est un système d'analyse et de synthèse qui modèle les sons d'impact, et les différents sons en entrée peuvent être plus ou moins bien modélisés par les algorithmes. Avec ces graphiques, nous pouvons évaluer de manière informelle la façon dont un son est modélisé par Impacter. Comme nous pouvons le voir, les sons de verre ne varient pas autant, et nous pourrions donc dire qu'ils ne sont pas modélisés de manière aussi optimale par Impacter que les sons de métal, de bois et de béton. Cela peut sembler évident, mais c'est une heuristique importante à garder à l'esprit lors du choix des sons pour Impacter - l'efficacité des fonctions de synthèse croisée dépendra du son choisi. En bref : certains sons varieront plus, d'autres moins !
Bien sûr, rien de tout cela n'est une preuve formelle de l'exactitude d'Impacter, mais plutôt une sorte d'anecdote permettant d'illustrer de manière intuitive toutes les différences entre une grande collection de sons, et, au passage, une bonne excuse pour expérimenter quelques techniques passionnantes de visualisation de données.
Autres questions
Il y a d'autres comparaisons que nous pouvons faire en utilisant la réduction de la dimensionnalité pour visualiser les possibilités offertes par Impacter. Nous avons notamment essayé de visualiser les variations produites parmi 88 sons de pas différents sur des tuiles, ce qui a donné un total de 7744 sons de tuiles. Là encore, l'examen des caractéristiques « MFCC++ » tracées par UMAP démontre l'utilité d'Impacter : les variations se produisent entre les sons originaux. Cela montre qu'un ensemble plus petit de ces 88 sons originaux mis dans Impacter a pu reconstituer une gamme de variations similaires à ces 88 sons originaux. La deuxième image montre les variations produites par seulement 22 des sons originaux, ainsi que les 88 sons originaux.
| VARIATIONS À PARTIR DE 88 BRUITS DE PAS | VARIATIONS À PARTIR D'UN SOUS-ENSEMBLE DE 22 BRUITS DE PAS |
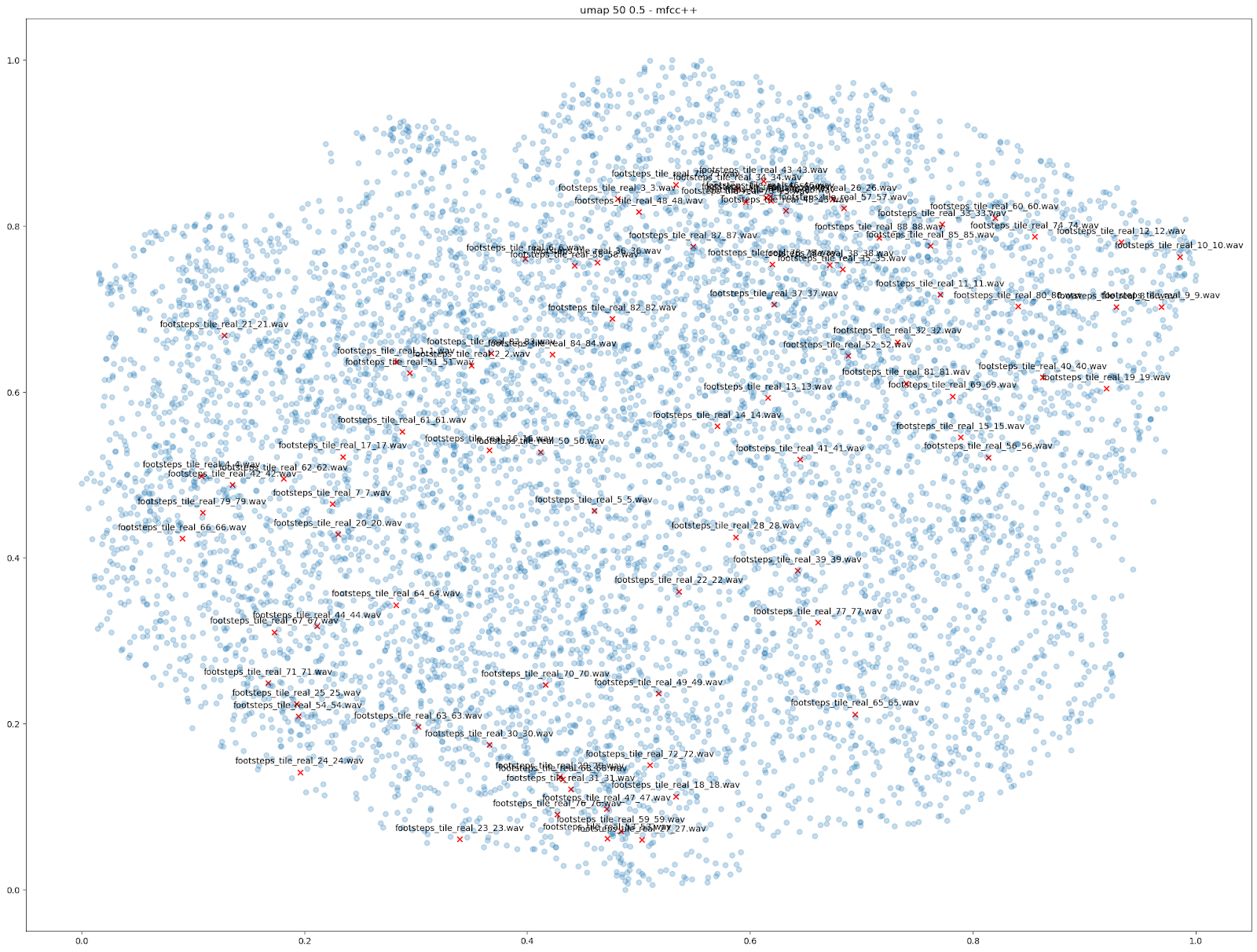 |
|
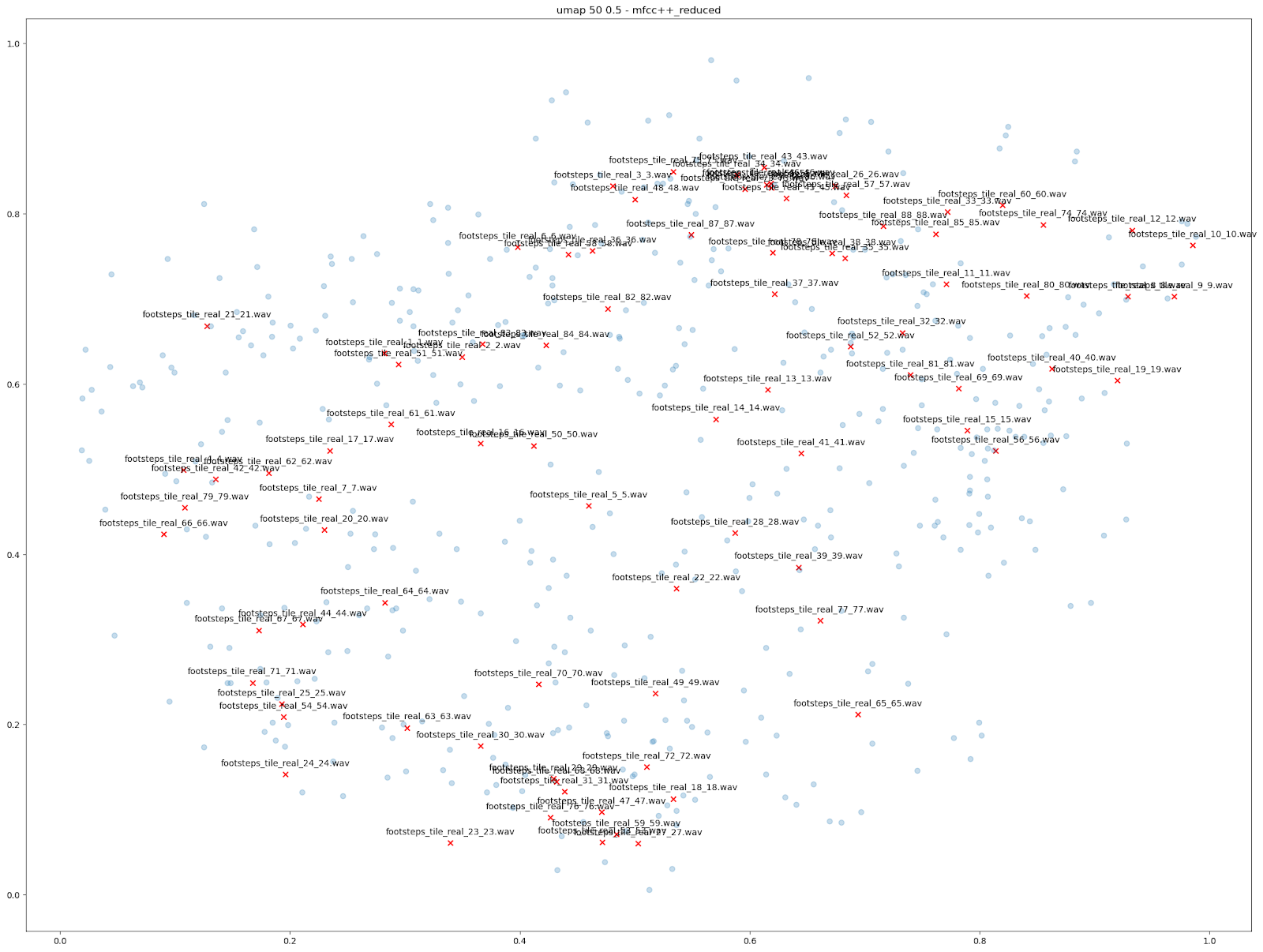
Pour voir l'image en grand format, faites un clic droit sur l'image puis sélectionnez « Ouvrir dans un nouvel onglet ».
Conclusion
Nous espérons que cet article vous aide à répondre à la question de savoir quel type de variations l'algorithme de synthèse croisée d'Impacter peut générer. Comme nous l'avons dit plus haut, il ne s'agit en aucun cas d'une preuve exhaustive ou statistique que toutes les variations sont absolument différentes, mais plutôt, comme nous l'espérons, d'une manière intuitive de regarder les grands ensembles de sons que le plugiciel pourrait produire, ce qui peut vous donner une meilleure idée de ce avec quoi vous travaillez lorsque vous utilisez Impacter.
Plus de détails...
Remarque sur le formatage des données
Les algorithmes de réduction de la dimensionnalité acceptent simplement une collection de listes de données, ou vecteurs. Puisque l'algorithme de réduction de la dimensionnalité est agnostique aux données d'entrée, et ne tient pas compte des dimensions dans les données d'entrée 2D comme les STFT ou les MFCC, nous pouvons de fait aplatir les données 2D, et même enchaîner plusieurs caractéristiques en partant du dessus, pour arriver à une seule liste à fournir à l'algorithme.
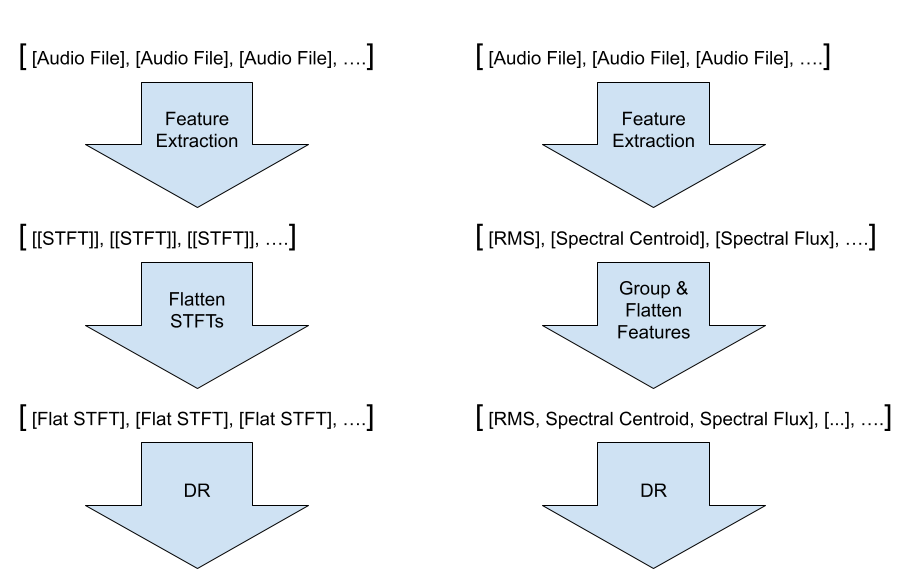
Algorithmes de réduction de la dimensionnalité
Il existe de nombreux algorithmes de réduction de la dimensionnalité qui acceptent simplement une collection de listes de données, ou vecteurs, qui, dans notre cas, sont les caractéristiques de chaque son que nous avons extraites lors de la première étape.
Les packages sklearn et umap-learn en Python (disponibles sur pip) fournissent des implémentations de nombreux et très utiles algorithmes de réduction de dimensionnalité que nous allons utiliser. Encore une fois, beaucoup de choses ont été écrites sur le fonctionnement de ces algorithmes, mais pour le bien de cet article, nous nous contenterons de fournir des liens pour une lecture plus approfondie.
t-SNE (t-distributed Stochastic Neighbor Embedding)
from sklearn.manifold import TSNE
tsne = TSNE(
n_components=tsne_dimensions,
learning_rate=200,
perplexity=tsne_perplexity,
verbose=2,
angle=0.1).fit_transform(data)
UMAP (Uniform Manifold Approximation and Projection for Dimension Reduction)
import umapumap = umap.UMAP(
n_neighbors=50,min_dist=0.5,n_components=tsne_dimensions,metric='correlation').fit_transform(data)
PCA (Principal Component Analysis)
from sklearn.decomposition import PCApca= PCA(n_components=tsne_dimensions).fit_transform(data)
MDS (Multidimensional Scaling)
from sklearn.manifold import MDSmds = MDS(
n_components=tsne_dimensions,verbose=2,max_iter=10000).fit_transform(data)
Ensemble des résultats
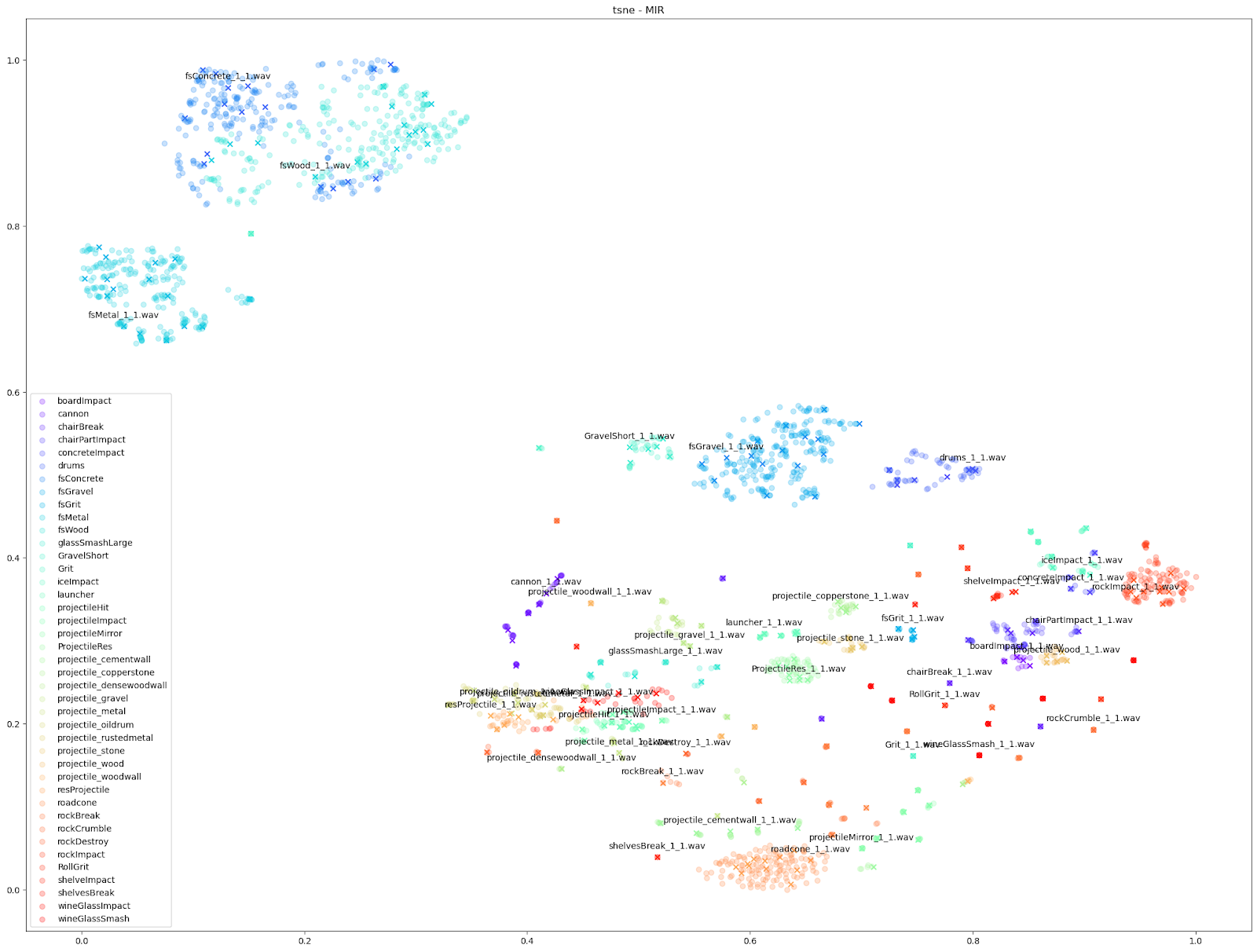
Pour notre test sur Impacter, nous avons comparé les quatre algorithmes de réduction de la dimensionnalité mentionnés ci-dessus. Nous avons exécuté chaque algorithme avec différents ensembles de caractéristiques audio en entrée : le STFT et le MFCC, le MFCC avec ajout de son delta et de son delta-delta (mfcc++) [3], et enfin un enchaînement de diverses caractéristiques audio (rms, centroïde spectral, crête spectrale, flux spectral, décroissance spectrale, ZCR).
| STFT | mfcc | mfcc++ | « Liste des caractéristiques audio » | |
| t-SNE | 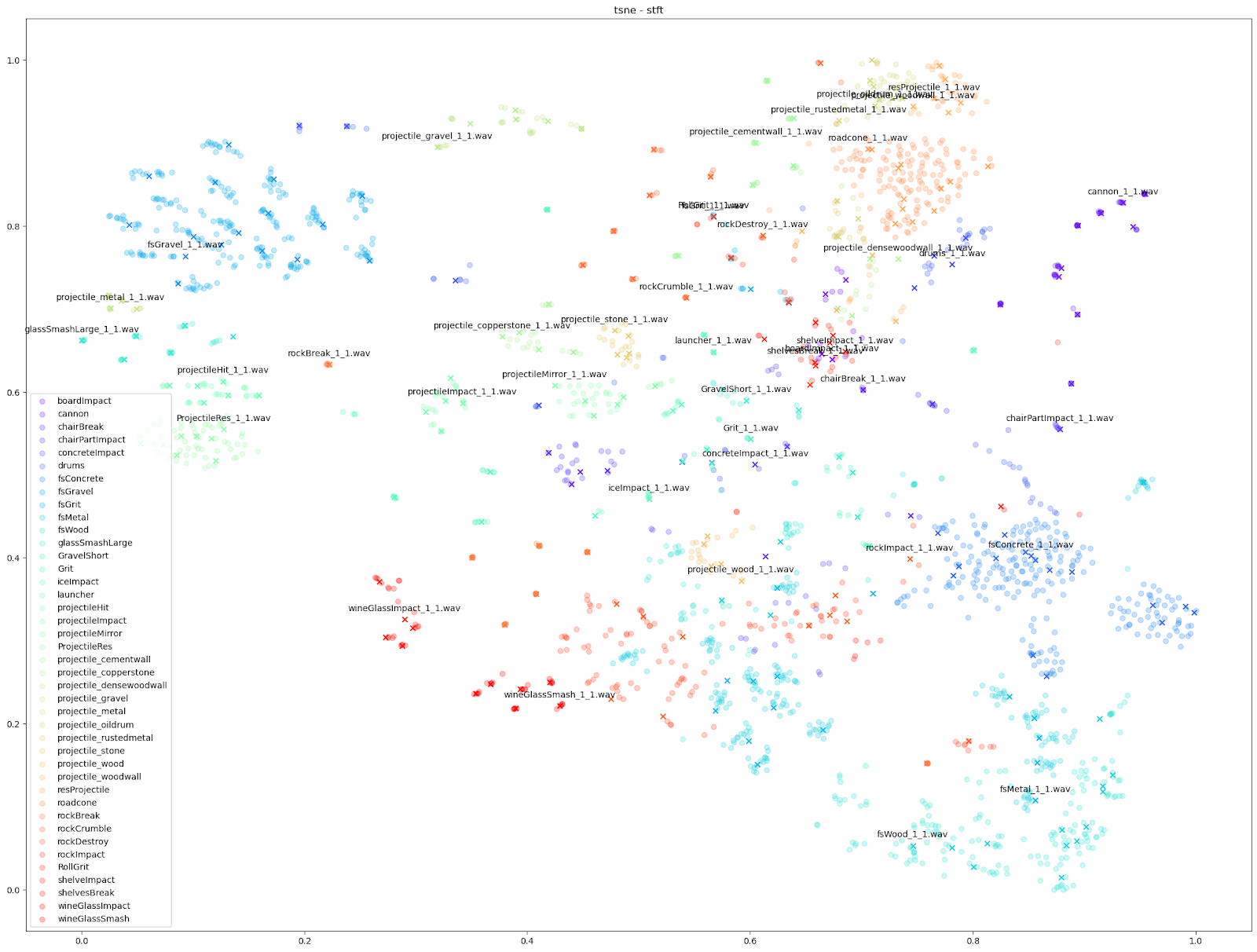 |
 |
 |
 |
| MDS | 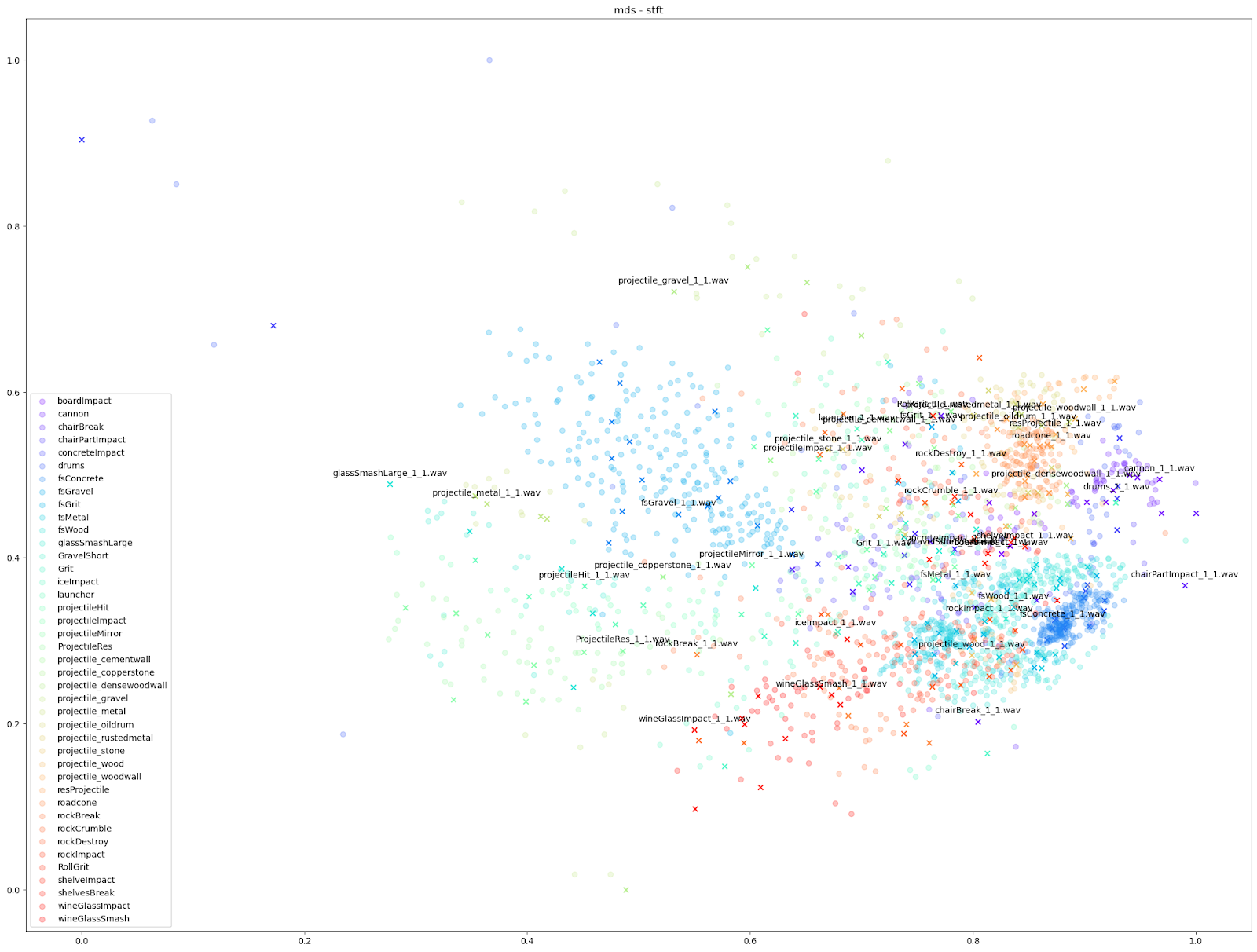 |
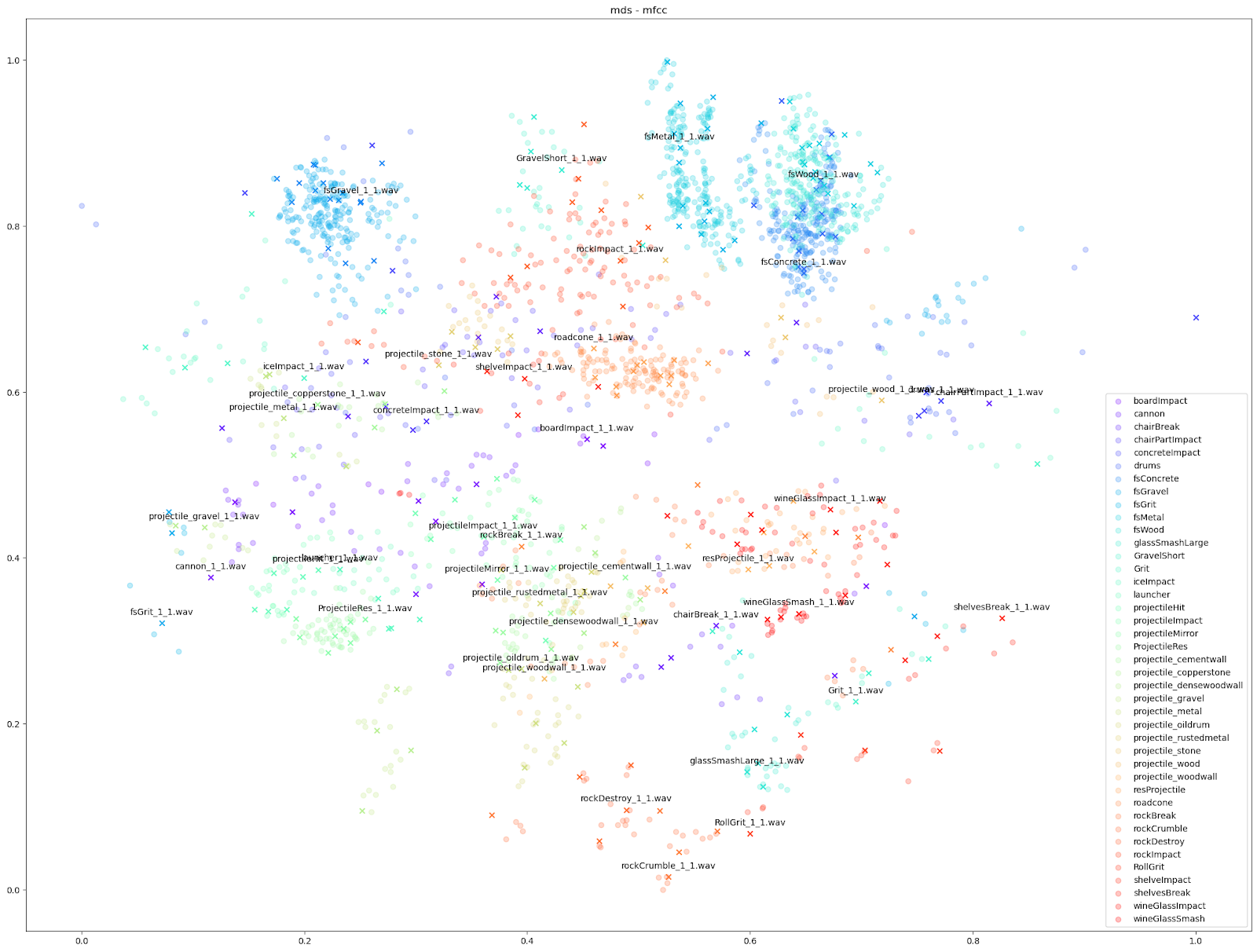 |
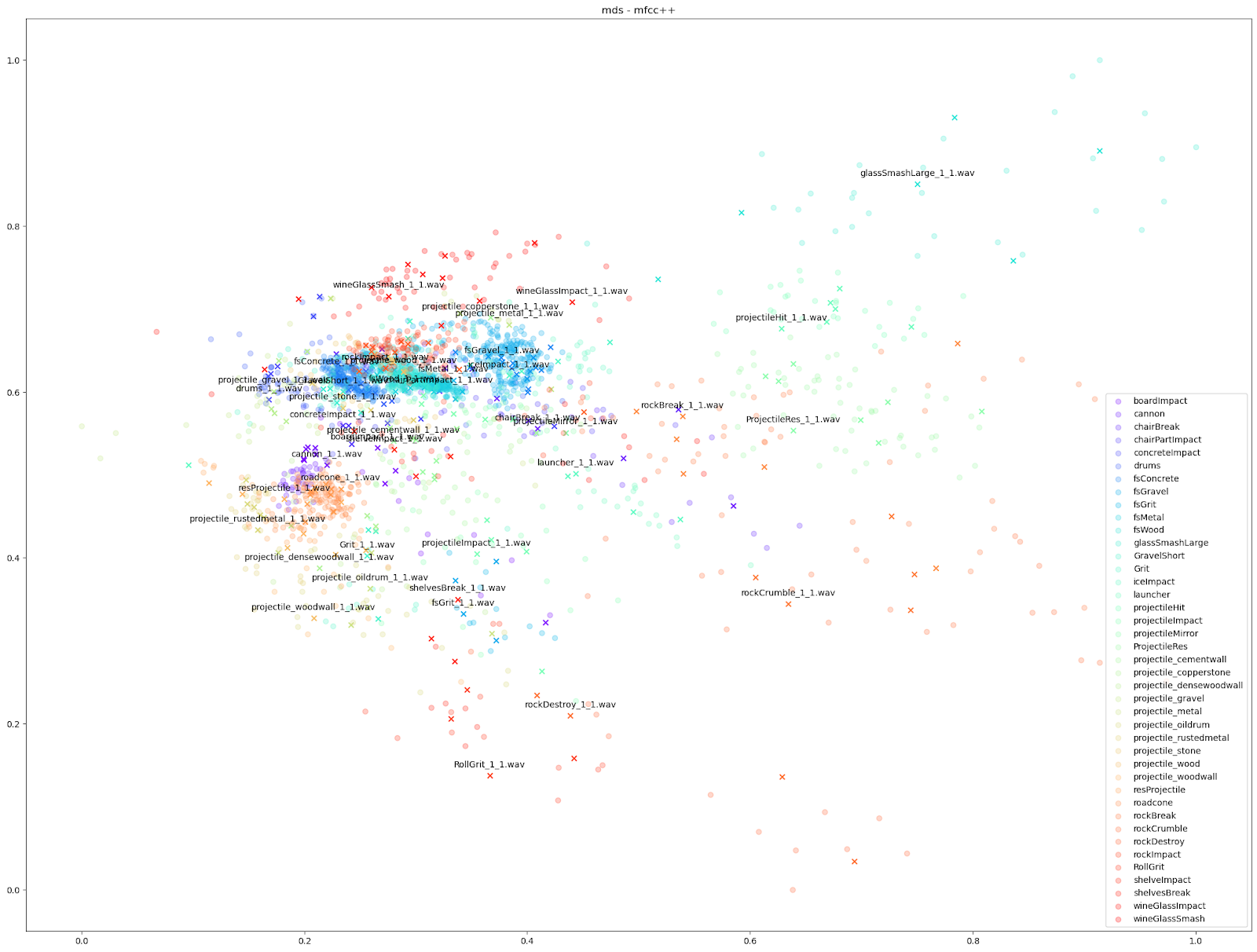 |
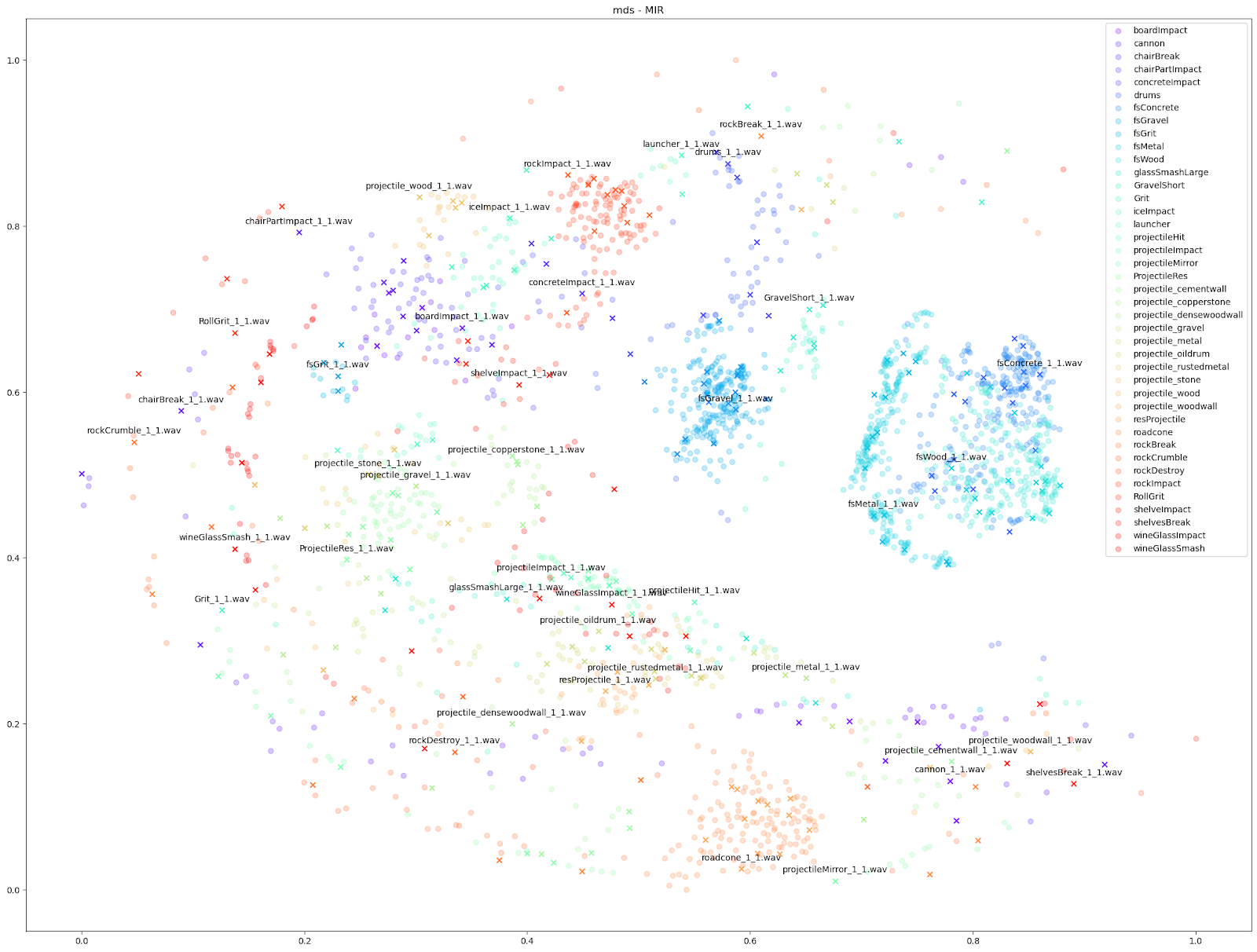 |
| PCA | 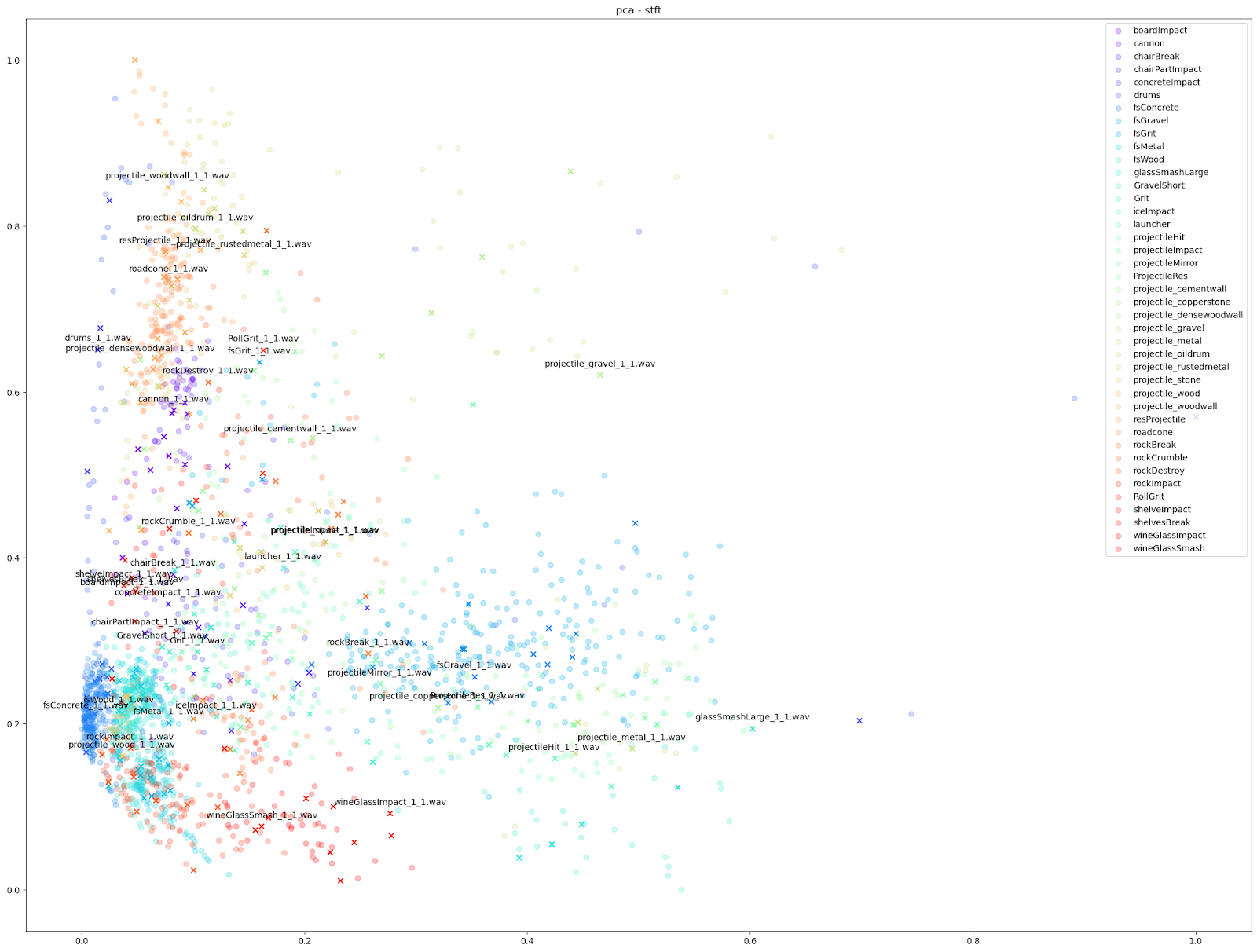 |
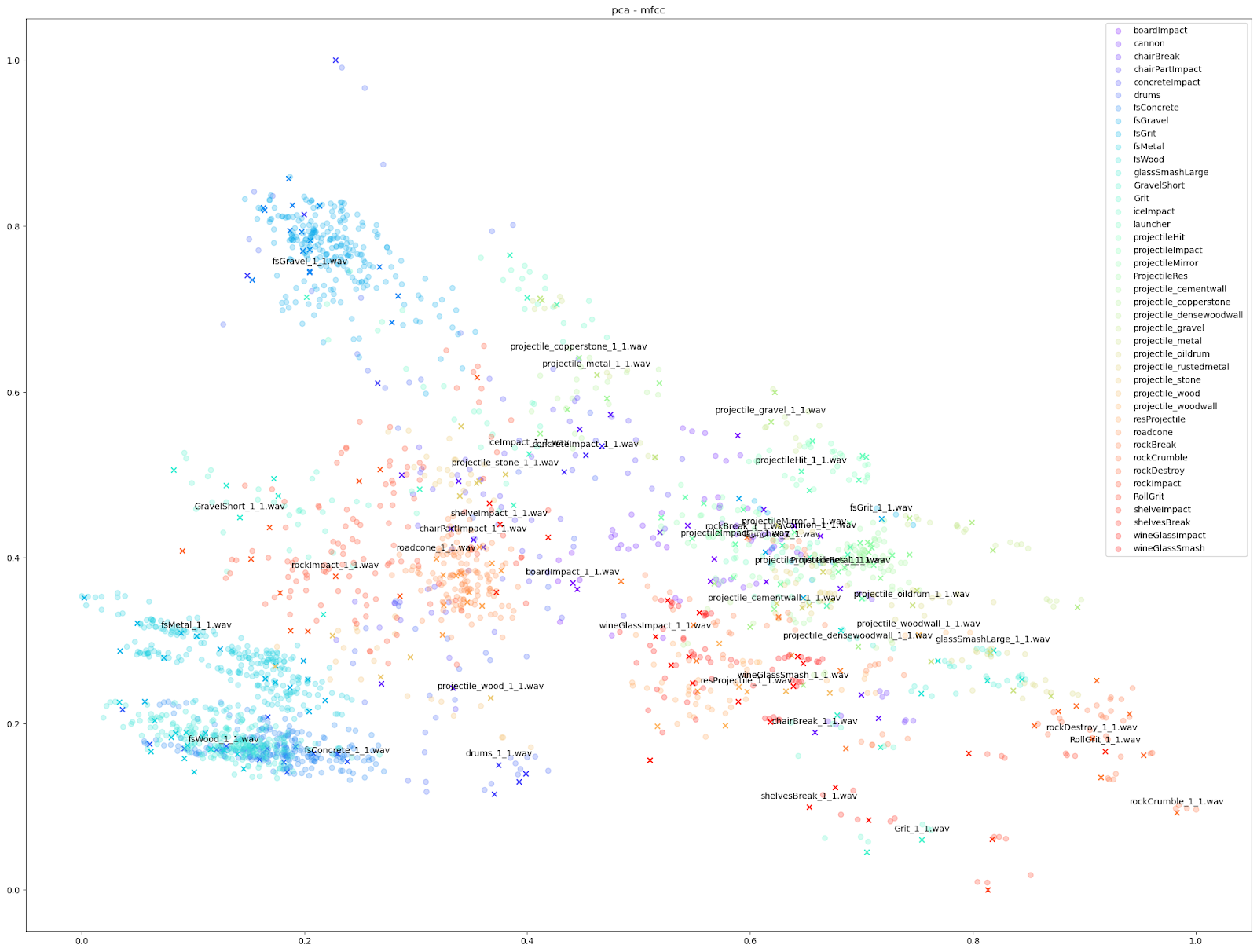 |
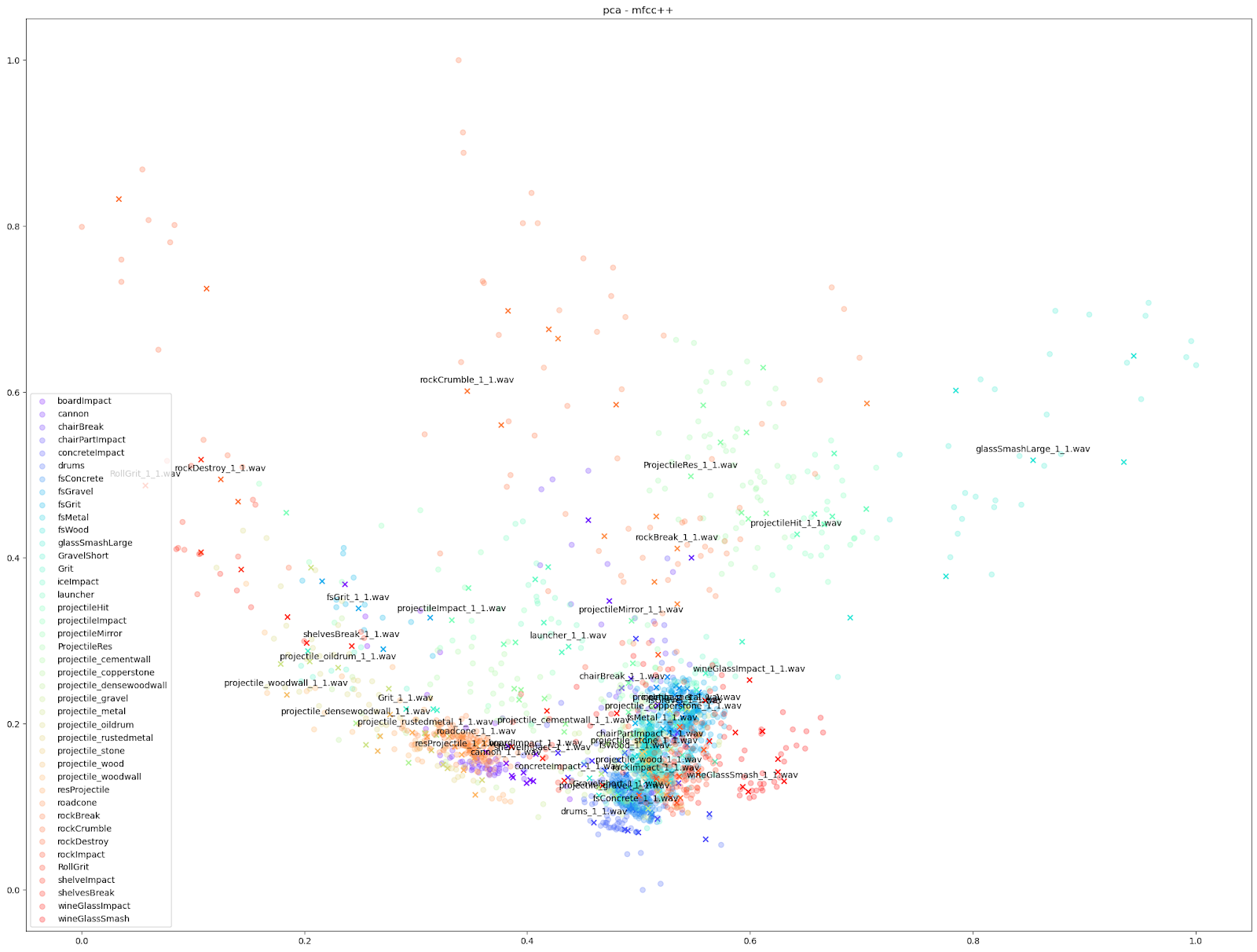 |
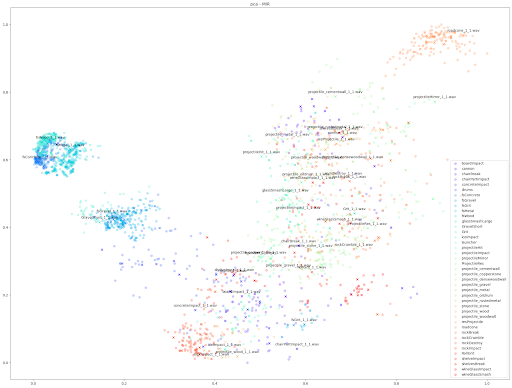 |
| UMAP 50 0.5 | 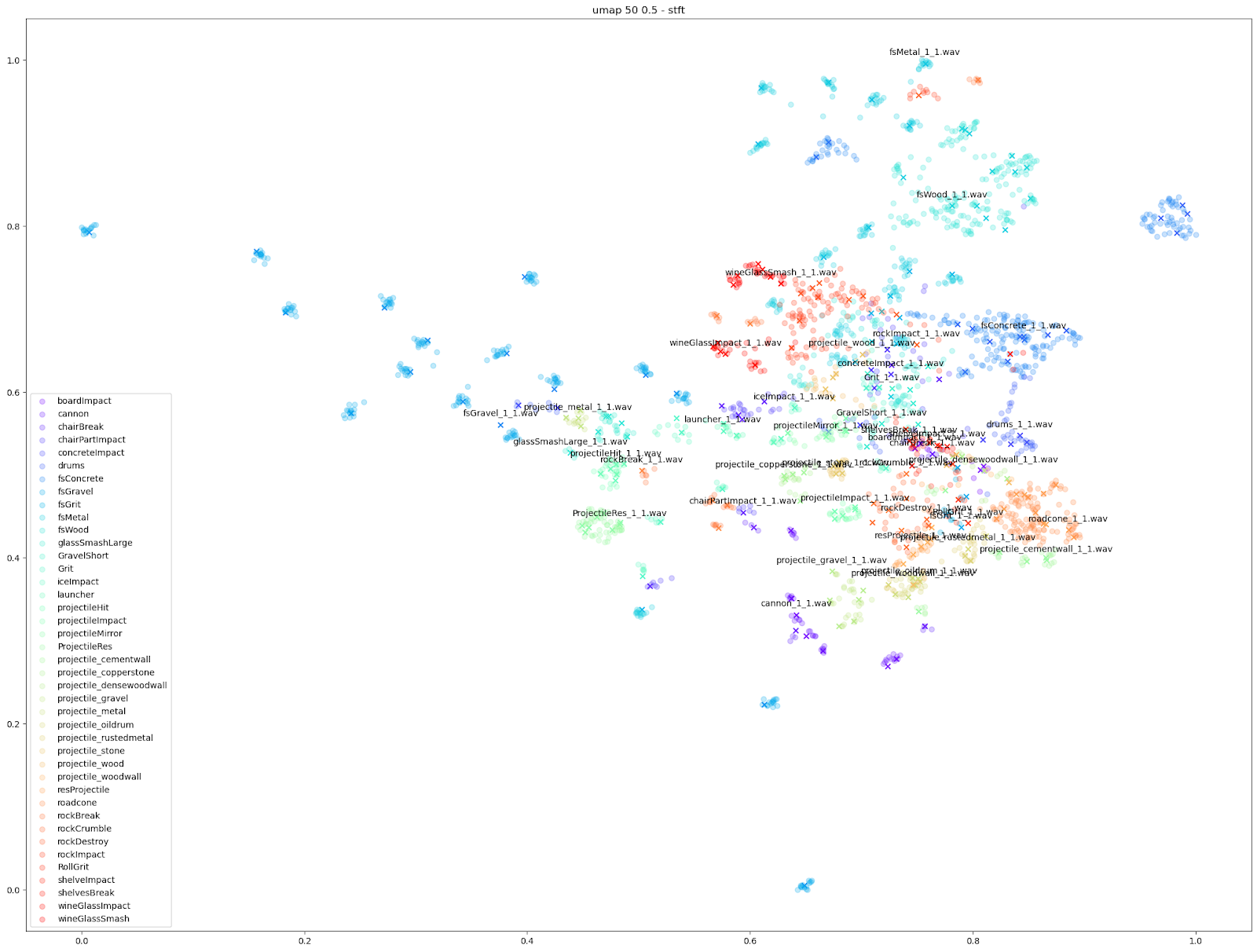 |
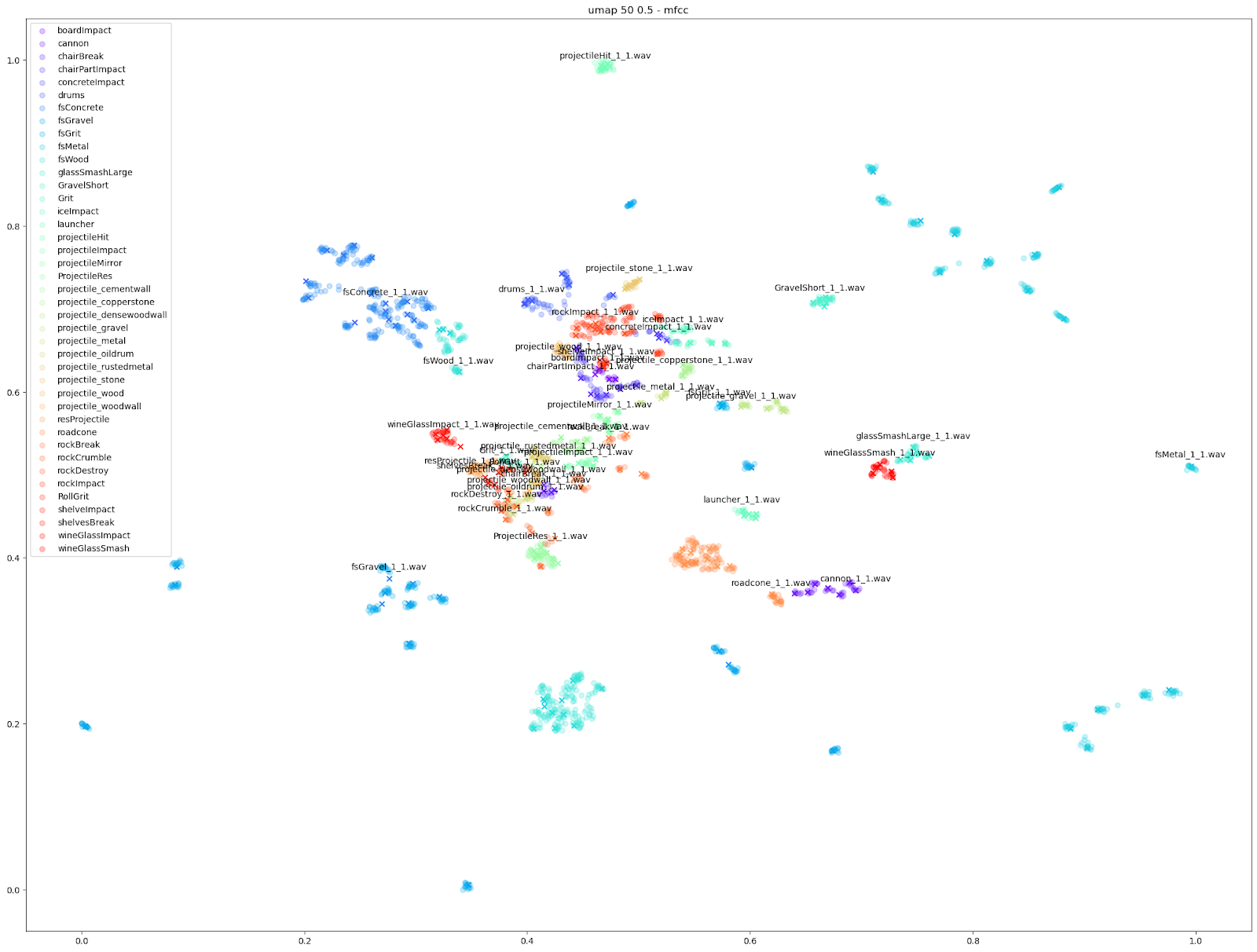 |
.png) |
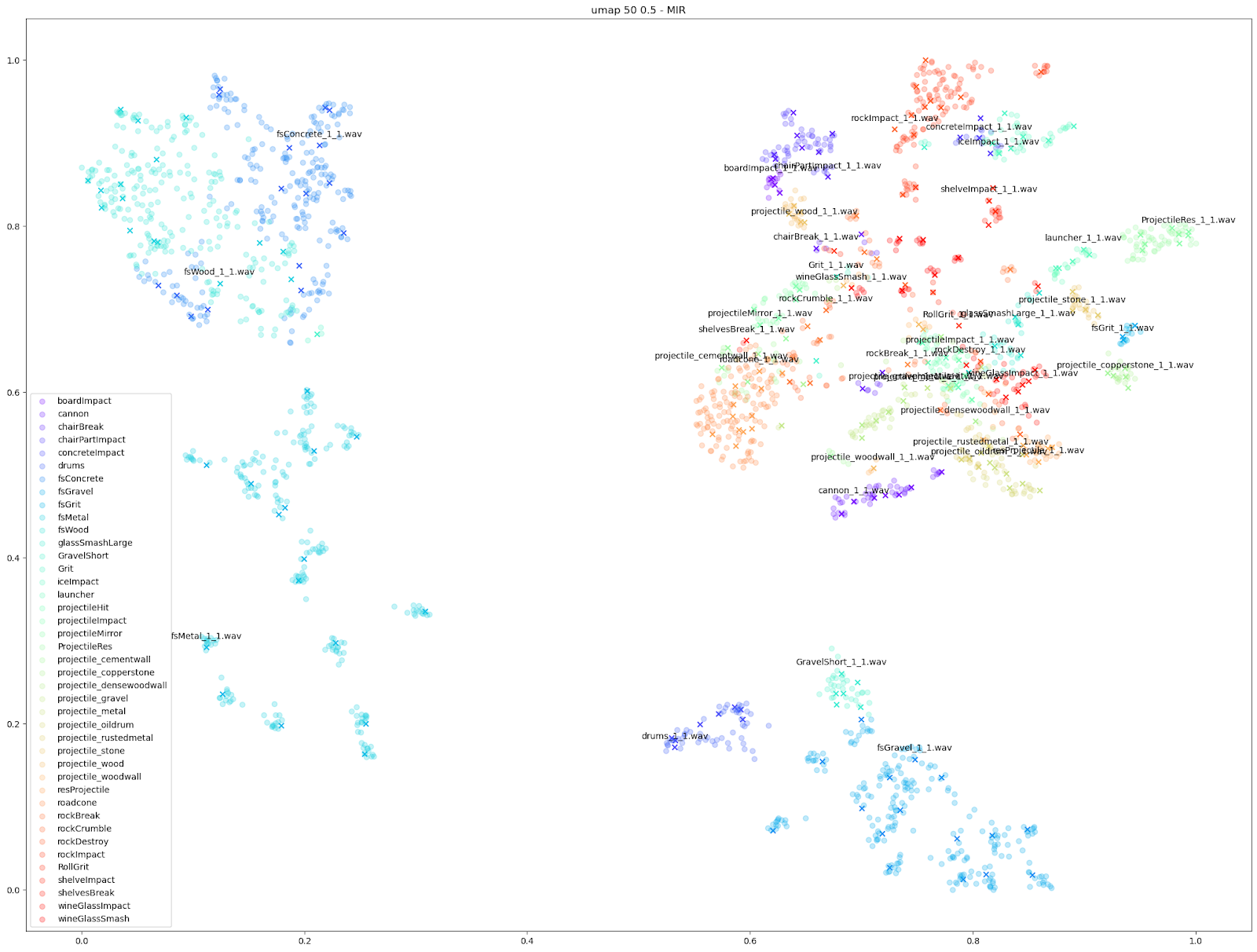 |
Pour voir l'image en grand format, faites un clic droit sur l'image puis sélectionnez « Ouvrir dans un nouvel onglet ».
Comme indiqué ci-dessus, nous avons constaté que les algorithmes UMAP et t-SNE fonctionnant sur STFT et MFCC++ (delta et delta-delta) ont fourni les graphiques les plus utiles.
Références :
[1] - Hantrakul, L. “H. (2017, December 31). klustr: a tool for dimensionality reduction and visualization of large audio datasets. Medium. https://medium.com/@hanoi7/klustr-a-tool-for-dimensionality-reduction-and-visualization-of-large-audio-datasets-c3e958c0856c
[2] - Audio t-SNE. https://ml4a.github.io/guides/AudioTSNEViewer/
[3] -Bäckström, T. (2019, April 16). Deltas and Delta-deltas. Aalto University Wiki. https://wiki.aalto.fi/display/ITSP/Deltas+and+Delta-deltas

Commentaires