
We live in a time where research and development of artificial intelligence is gaining a significant momentum. It is no longer just a subject of science fiction novels and movies. Increase in global internet accessibility, improvements in computing hardware, machine learning and neural networks have all contributed to the situation where we are now. Achievements in this field are astonishing. AI is here and it’s going to stay!
Current accomplishments in AI have had a positive influence on game development, including game audio. I want to share with you an example of how developments in AI have helped our team save time and effort in voice over production for our latest project.
Developed in cooperation between Mad Head Games and Wargaming, Pagan Online is a fast-paced hack-and-slash action RPG set in a fantasy universe that is inspired by Slavic myths. Besides coop missions, hunts and assassinations it has a rich campaign with over fifty hours of content. At the time of writing this article, the game is in early access, available for PC through Steam and Wargaming. It is definitely Mad Head’s most ambitious project so far.

PAGAN ONLINE: In-game screenshot of campaign level with Kingewitch as player character
The history of Mad Head Games
This story cannot be told without mentioning at least a brief history of our studio. Mad Head Games (MHG) is located in Serbia and was founded in 2011 by a small group of talented friends. Until this year, the studio was mostly recognized for the creation of HOPA (Hidden Object Puzzle Adventure) titles like Rite of Passage and Nevertales. With the business growing, more and more people joined the studio and with most of them being hardcore gamers themselves, there was a growing hunger for a different kind of project.
More than three years ago, we started a project today known as Pagan Online. The development of this game was mostly driven by our common and deep passion for gaming and Slavic lore. No one really had any experience with Unreal Engine or multiplayer game development. We all had learned along the way, including the audio team. Before Pagan Online, we only created sound effects for HOPA and mobile games using our proprietary game engine with its own scripting language.
All of our sound designers are full-time, in-house MHG employees, and we share the following philosophy.
"The one who creates the sounds is the one who implements them in the game."
This means that all of our sound designers have to be familiar with basic programming and source control principles. We were therefore able to quickly adapt to a new engine and to learn to use Wwise as our middleware.
Practical learning of course has its pros and cons; we may not have learned everything the 'right' way. I'm preempting with this because how we chose to do things may or may not be academically the best of methods. However, we learn along the way with the best intentions. While we didn’t have any prior experience in the production of AAA titles, we realized we had a need for automating at least some parts of our pipeline. This drove us to exploring AI.
The Situation
HOPA games are very much story driven, which means they have a lot of dialogue. Since it's hard to find local actors who are native English speakers, our studio made the logical decision to outsource the recording of voice-overs. Our team only had to edit and implement them in the games. When the development of Pagan Online started, we just continued to use the same workflow. Let’s explore our production pipeline.
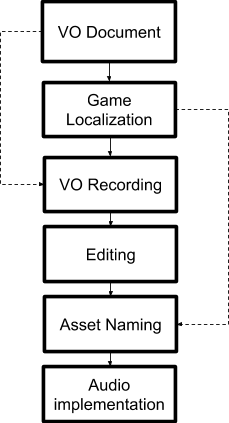
Original VO production pipeline at Mad Head Games
As you can see in the picture above, everything starts with the narrative designer who is responsible for writing the lines. Programmers then implement the dialogue text into the game. They put all of the lines in one localization file and assign them unique identifier strings.
ch1_archives:dlg_horrible_11 "Something horrible took Riley!"
Example of a dialogue line inside the HOPA localization file
After that, the VO document is sent to the actors. Each actor records their lines using just the written directions. They send us back raw, unedited, long audio files with multiple takes. We then edit the files, choose the best performances, and name the files. Each file has to be named using a unique name based on the identifier from the localization file (i.e. vo_ch1_archives_dlg_horrible_11.ogg). This means that the voice editor must manually name every single audio file. This process is slow, dreary and time consuming. When we were working on HOPA games exclusively, it was not a big problem, but when we started working on Pagan Online, the issue started to emerge.
The amount of dialogue lines in this game is incomparably larger and because we are using Wwise and UE, we need to name the audio files, import them, create Sound Voice containers, create events, put them in proper banks and finally create all those events in UE again. Also, there is no global human readable localization file in this project. Instead, we use a bunch of UE’s DataTables which are not very reader-friendly. The frustration instantly skyrocketed.
We looked at Nuendo’s feature called Rename events from list. We thought that something like this could help us, but it requires you to organize the audio items in the order they appear in your list (game). Because we are outsourcing voiceover recordings, we don’t have the luxury of having all actors in one room performing together. We also don’t have the ability to direct their acting in realtime. As a result, we always get files from different actors at different times and we cannot hear various characters speaking to each other until all actors record their lines. However, even if we waited for that, the time it would take to edit the dialogue lines in the order they would appear in-game would be tremendous. Instead, we wanted a tool that could allow us to edit and name the files as they came in from each actor.
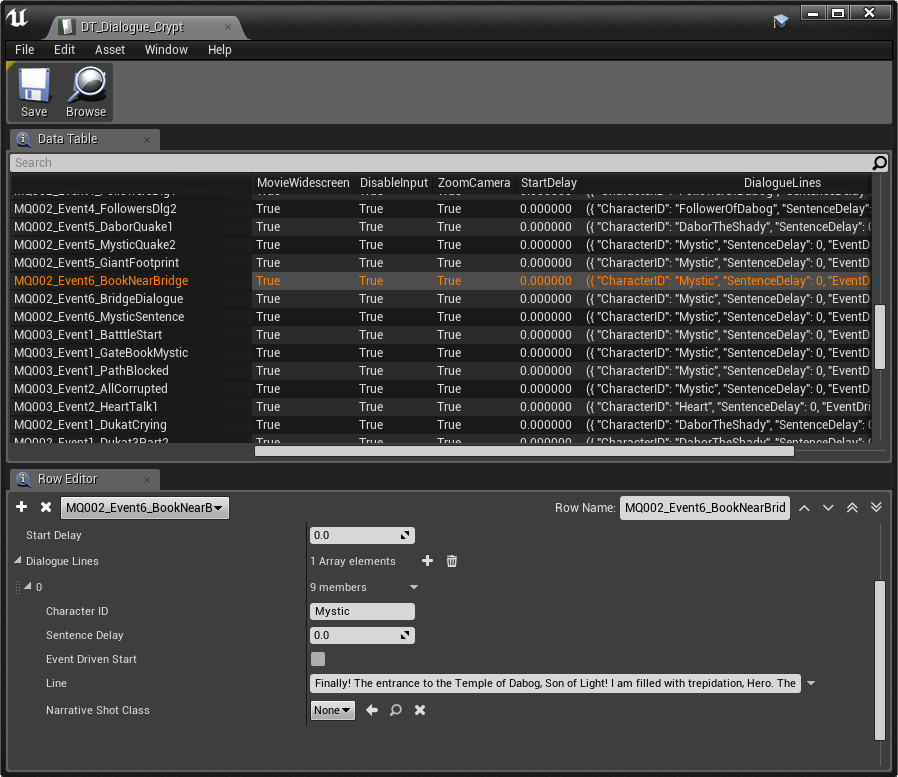
Typical dialogue DataTable inside UE
After analyzing our situation in more detail, I created a list of things that we needed to solve in order for our production and implementation of voice overs to become faster and more efficient.
- Datatable naming convention
- AkEvent naming convention
- Automated event triggering
- Automated audio file naming
- Automated Wwise audio import process
- Automated Wwise event creation
Most of these things were fairly simple to solve. Programmers created a blueprint which searches for AkEvent by string, based on dialogue ID from Datatable. We just needed to agree on some basic naming rules and to be consistent. I thought automating the creation of Wwise containers and events would be especially tricky, but then I found out about using TSV in Wwise, and this issue was out of the way.
Automated audio file naming - The solution
So, what are you actually doing when naming audio files manually? You first listen to the audio, then you find the text you heard in a certain file and give it the appropriate name according to the rules your team agreed upon. So there are basically three processes: listening, searching and naming. The first one is crucial. It is not enough to just listen. You need to have the ability to understand the message which is encoded in the audio. The message is simply text which your brain can convert from sound to meaningful text. So, if we want to automate this process, we need to have a system that can convert recorded speech into text. This is a point where we could use some help from AI. Luckily, this kind of system already exists and you can guess what it's called: Speech to Text. Speech recognition is not a new idea, but lately, especially with the popularity of smart phones, speech recognition became really good and accessible.
On the other hand, voice is very dynamic in nature. Intelligibility of speech is an issue people encounter even when talking with each other. Machines have even more trouble with this because they still can’t understand the context and the intonation of speech like people do. It’s not going to be like this forever, but until then, we still need a way to compare what an algorithm understands with what is actually being said. We need to rate the amount of matching. So to recap, the idea was to implement two systems:
-
Speech to text
-
Approximate string comparison
The most important aspect for this idea to work was usability. This meant that it was not enough that technologies exist. I needed to find a way to utilize them for our purpose and to be able to do this while editing files, inside the DAW.
At MHG, we are using REAPER which is famous for its flexibility and extensibility, so it was a perfect platform for this kind of endeavor. REAPER supports Lua, Eel, and Python languages for scripting and while the first two are faster and more portable, Python is the one with a vast database of modules.
I started exploring different solutions and after weeks of testing and failures I created a prototype solution. ReaCognition, a Python script for REAPER which uses SpeechRecognition and fuzzywuzzy string matching to automatically name dialogue files.
ReaCognition
The script works by scanning the selected part of your audio file and applying speech recognition to it. What you get back is a text which is then compared to a special database with all of the dialogue lines from your game. You need to prepare this database prior to running the script. When a match is found, the script takes the ID of that dialogue line and uses it to construct a unique name for the audio file.
The (new) procedure
In the image below you can see our new dialogue production pipeline. The process is pretty much the same, but with the crucial addition of ReaCognition. I will now describe all the steps in detail so you can have a better understanding of the new parts.
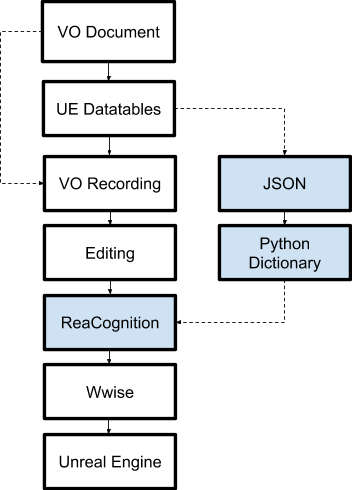
1. VO Document
The narrative designer writes all the lines for the game and puts them in one organized document.
2. UE DataTables
Programmers implement lines from the VO document into the game using a DataTable.
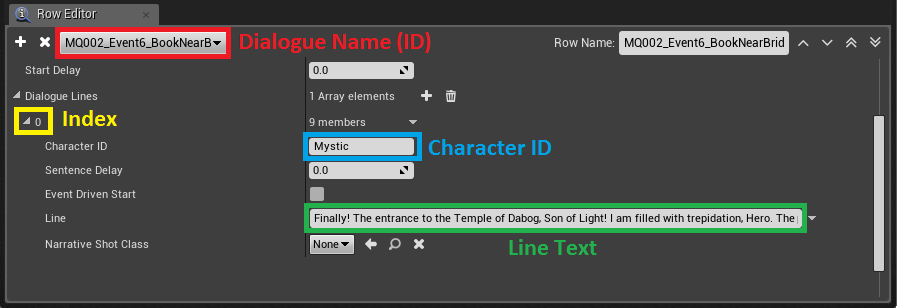
Details of particular dialogue line inside DataTable
Above you can see the contents of one selected dialogue line inside a DataTable for the Crypt area. The data is organized in rows with two columns. Datatables function like dictionaries. On the left are the keys and on the right are the values. Every dialogue has its own unique name (ID) and it consists of multiple lines. Each line has its own index and Character ID. In runtime, a special blueprint (BP_DialogueManager) extracts the values from datatables and creates a long string using the formula. Below, you can see the formula for creating AkEvent strings.
FORMULA: DLG_(Area)_(DialogueID)_(Index)_(CharacterID)
Example:
DataTable: Crypt
ID: MQ001DukatAppears
Index: 01
Character: Dukat
Line: Hello there! How can I help you?
AkEvent name: DLG_MQ001DukatAppears_01_Dukat
AkEvent name string is used for triggering an AkEvent. We decided to use this approach so that we don’t have to create hundreds of AkEvent assets inside our UE project. This way, we just needed to make sure that the Event exists inside the Wwise project and that the appropriate dialogue bank is loaded.
BP_DialogueManager creates a text box and triggers the AkEvent
3. VO recording and editing
Actors record their lines and send us back long audio files. VO editors edit the files, pick the best takes and apply corrective and creative processing.
4. ReaCognition
4.1 Creating a dialogue database
Before using ReaCognition, we first need to create/update our ReaCognition dialogue database. It’s a special Python dictionary file and it contains the latest dialogue lines from all dialogue DataTables. In this file the keys are the names of AkEvents and the values are the lines themselves. Creating this database is a two-step process. We first select all dialogue Datatables in UE and export them as JSON files.
Context menu for DataTables inside UE
Then, inside REAPER, we run a special script which gathers the data from all JSON files and stores them into one big dictionary. This dictionary will be used for comparison with AI recognized text.

Console message output after successfully creating a dialogue database
4.2 Naming the items
At this point we are ready to start naming audio items inside REAPER. The voice editor selects the item or a part of the item (using time selection) and runs the ReaCognition script. After a few seconds a message box similar to the one in the image below appears.
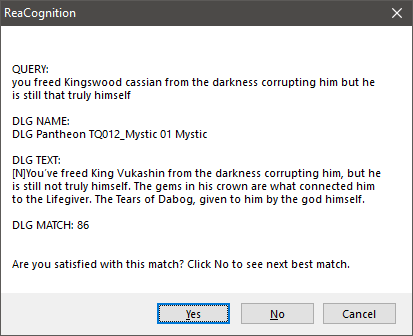
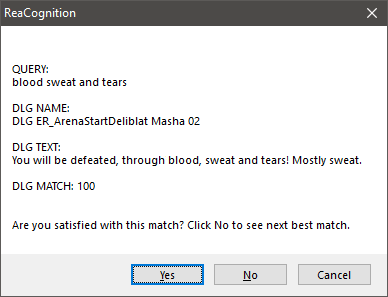
Typical ReaCognition output message box
- QUERY is the text which AI recognized from selected audio item.
- DLG NAME is the name of the found dialogue line.
- DLG TEXT is the line text.
- DLG MATCH is the percentage of matching between QUERY and DLG TEXT.
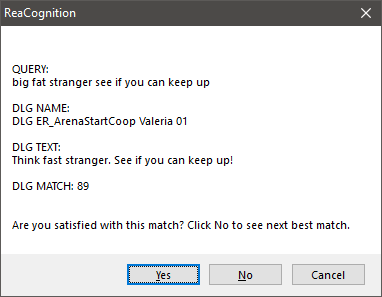
Example of AI misunderstanding certain words
In the example above you can clearly see that some words are completely misunderstood. This is not a problem as long as there are other words that are understood correctly. The script always looks for the closest match to the query. In most cases the first result is the one you are looking for, but if that’s not the case, you can click ‘No’ and the next best match will be displayed.
When you are satisfied with the result you just hit ‘Yes’ and your audio item gets a new name.
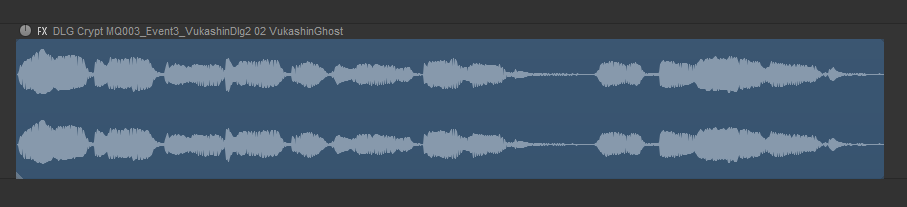
Audio item name after using ReaCognition
NOTE: You can see that there are spaces instead of underscores between the data values of formula parts of the name. The reason for this will be explained later in this article.
There are two approaches for using ReaCognition - safe and fast.
The safe way is to always scan the complete voice over line. This way you are sure that you will get the best result, but the longer the audio, the longer it takes to get the results back.
The fast way is to select just the most recognizable and unique part of the VO line. The problem with this is that the amount of matching is dependent on the uniqueness of the selected audio part across the whole dialogue database. It is crucial to choose wisely. You can see the example of this approach below.

Scanning just the part of voice over with ReaCognition
ReaCognition output after scanning just a segment of voice over
Manual ReaCognition
There are situations where AI simply cannot understand the content of the audio. For such cases, I created a special mode. The user selects the audio item and then creates the query manually by typing it in the text box. There is no need to type punctuation symbols. Casing is also ignored, even the order of words can be shuffled. The only important thing is to choose enough characteristic words from the voice-over you are trying to ReaCognize.

Entering query manually
5. Wwise - Creating containers and events
After all items are properly named, it’s time to render and import them into the Wwise project. Rendering is done using REAPER’s flexible rendering engine. In our case, we rendered all selected items to an absolute location using $item wildcard for the filename.
Importing was a little more complex to solve. This step of the process is something that I automated using TSV files. If you are not familiar with this in Wwise, it’s a system for container and event creation using a text list with the paths of audio files and predefined structure for containers and events. It is very powerful and I would say the only thing more powerful than TSV is WAAPI, but at the time of creating ReaCognition, I was not aware of it.
The complete procedure is to first select all audio items, render them and then run a script which will create a TSV file and automatically import it into Wwise using a command line.
In the examples of ReaCognition output above, you’ve probably noticed that the generated names of audio items are not completely space free (i.e.”DLG MQ001DukatAppears 01 Dukat”). AkEvents must be named with underscores only, but audio files and containers don’t have that kind of a limitation. I used this advantage to generate a TSV file based on the information encoded into selected audio items’ names. Spaces are used to parse the information. Each part of the name corresponds to a certain container.
<WorkUnit> Dialogue
<Actor-Mixer>Dialogue
<Actor-Mixer> Map
<Actor-Mixer> DialogueID
<Sound Voice>Filename
<Sound Voice>Filename
<Sound Voice>Filename
Black lines are absolute paths and blue lines are relative paths (different for each audio item). The same logic was applied for creating events, but spaces had to be replaced with underscores.
Structure of Dialogue WorkUnit in Audio category - created automatically
6.Unreal Engine
The last step is building dialogue banks with the newly created Events. Blueprint automatically triggers the audio when the dialogue box appears in the game.
Conclusion
I hope that I succeeded in describing what the problem in our VO production pipeline was and that I was clear enough in explaining how we solved it. If you like our solution and would like to do something similar for your project, please feel free to contact me. Right now, ReaCognition is a tool created just for one specific project, but my plan is definitely to make it publicly available in future, especially if there is a significant need for such a tool.
Once again, I don’t claim that this workflow, or even ReaCognition, is the best solution for the problem, but this is the way we handled it. I’m sharing this with the game audio community so we can all learn from each other. MHG audio team is open for suggestions and comments regarding our process. Perhaps you can help us improve it so we don’t have to use ReaCognition at all. Our team does not have much experience in AAA game audio production and we might have done something wrong. If that’s the case we would certainly like to know.
Using speech recognition is just one small example of the potential power of AI in game development. I’d like to believe that I at least inspired you to imagine a brighter and more exciting future for the game development industry, one where every possible task is automated and where people use just their creativity. In that kind of environment, quality will be the only factor for success.

Commentaires
Simon Pressey
August 26, 2019 at 09:14 am
Hi Nikola, Thank you for your blog post. I am impressed by your solution ! I would be interested to play with ReaCognition I would caution against using spaces in file names, that are version controlled, as this has for me caused problems in Perforce during localization. Something to do with how whitespace is interpreted in different languages.