
If you’ve scanned across the list of new features for Wwise 2023.1, and indeed, there are many, you may have come across a curious phrase: “Revised Aux Send Model”. What on earth is that!? Well that, my good reader, is the subject of this article. I will outline the changes made to Wwise Spatial Audio, explain how it works under the hood while spilling the nitty details and underlying motivations. A word of warning, however, things may get a bit technical. This article is primarily targeted towards users with at least some experience setting up Rooms and Portals or creating Room Aux busses in Wwise. If you are new to Spatial Audio, you may get more out of this article if you first download a sample project from the Audiokinetic Launcher and have a go at setting up some Room reverbs inside an Unreal or Unity map.
For Wwise 2023.1, we have made an incremental improvement to the spatial audio signal path - both in terms of usability and flexibility. Here, when referring to the signal path, I am specifically referring to the way busses are automatically created and routed from one to another. Wwise Spatial Audio sits on top of the Sound Engine, passing instructions on how to process and render audio, in a manner that matches what is going on in the simulation. Generally speaking, the bus routing structure is based on the placement of Emitter, Listener and Room Game Objects within the virtual world.
The Wwise Sound Engine provides a flexible framework for spawning voices and busses within the context of a Game Object. The voices and busses, which are connected with Auxiliary Sends or direct output connections (collectively just “connections”) can be visualized in the Voice Graph of the Wwise Authoring Tool. The Voice Graph and the Voice Inspector are excellent tools for understanding what is going on inside the Sound Engine.
I have provided some background information where relevant, but for a complete overview on how Spatial Audio routes audio within the Sound Engine, refer to the Propagation Paths in the Rooms and Portals Signal Model section of the documentation. You may wish to open this into a new tab and refer back to it.
For the Revised Aux Send Model in Wwise 2023.1, here are our high-level design goals:
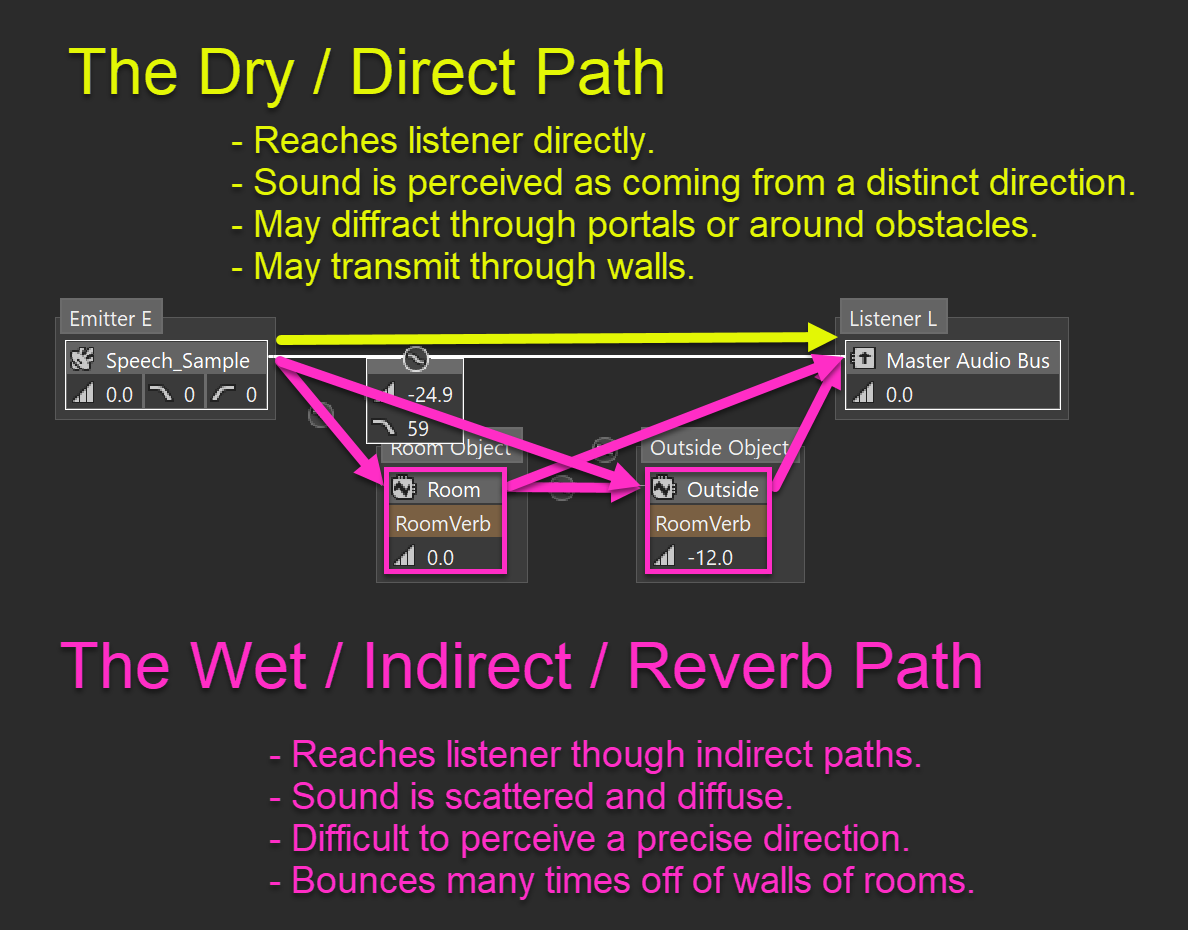
- We want to allow all rendering parameters, including attenuation, diffraction and transmission curves, to be customizable per sound. In real life, sounds follow a strict set of rules governed by the laws of physics. However, in video games, it is often necessary to customize sounds to achieve a specific creative effect. Some sounds, for example, must unnaturally propagate further than physics would dictate, for example to make dialogue audible. Furthermore, since we only have a finite dynamic range, sounds that should be perceived as louder in the virtual world must be designed with a flatter and longer volume falloff than quieter sounds. In Wwise 2022.1, it is indeed possible to define per-sound attenuation curves on the game-defined auxiliary sends, which are used to control the amount sent to the room bus chain (the “wet path”). However, diffraction and transmission curves for the wet path were separate and distinct. They had to be shared by all sounds routed through a room, which was a bit awkward and burdensome. This was something that had to change.
- We do not want people to have to author more curves than necessary, nor do we want people to have to compromise when authoring curves. It is not always possible to design a single curve for a room that will work for all sounds within the room. If there are, for example, both footsteps and gunshots playing in the room, any curve that is shared by all sounds in the room would likely be a compromise.
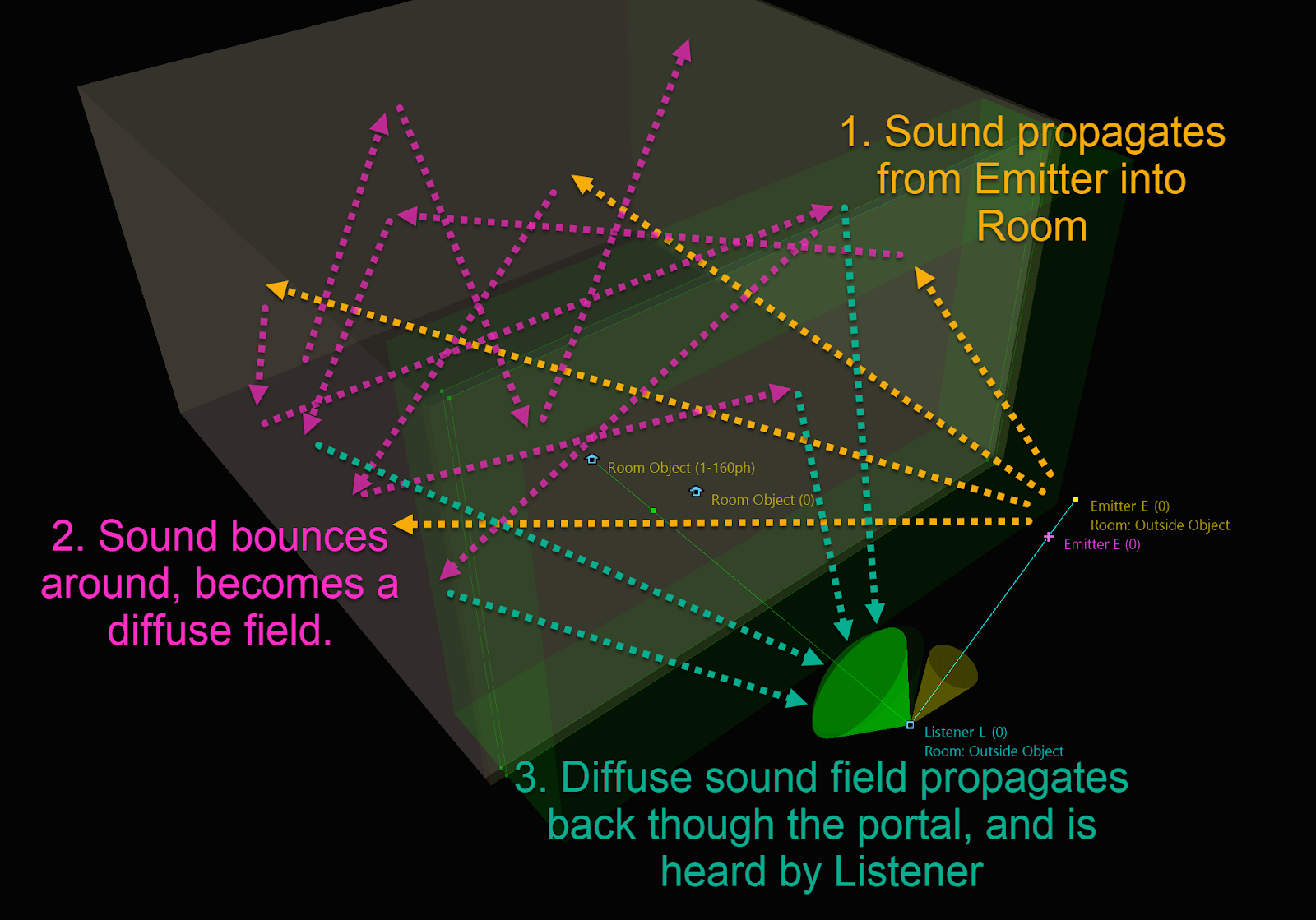
- We want to model the acoustic phenomenon of sound propagating into a room and then back out again. If you go up to the mouth of a cave and yell loudly or pop a balloon, you hear the sound reverberating into the cave and then back out again. Prior to Wwise 2023.1, you would only hear the cave reverb when either the emitter or listener were in the cave.
- We want to accomplish all this while maintaining 1 auxiliary bus and 1 reverb instance per room. Creating a unique reverb bus and reverb instance per voice would make things a lot easier. We could then precisely customize the output of each reverb to the unique characteristics of the emitter. Unfortunately, this would incur a significant and unacceptable increase in CPU usage.
So, what has changed for the Revised Aux Send Model in Wwise Spatial Audio in 2023.1?
For the wet path, all rendering parameters, including the evaluated diffraction and transmission loss values, have been moved to the input of the first Room Bus in the chain. Assuming that effects on a room bus are linear and time-invariant, which is typically the case for reverb effects, it makes no difference whether we filter/attenuate sounds before or after the bus. The resulting audio buffer will be exactly the same.
Moving rendering parameters “upstream” to the input of the Room Bus serves to accomplish design goal 1, while also supporting design goal 2. Since we have one input connection to a room bus per sound, each sound will be able to apply rendering parameters specific to the sound. Voila! Attenuation curves on Room Busses are no longer necessary, and we have reduced the burden of authoring curves.
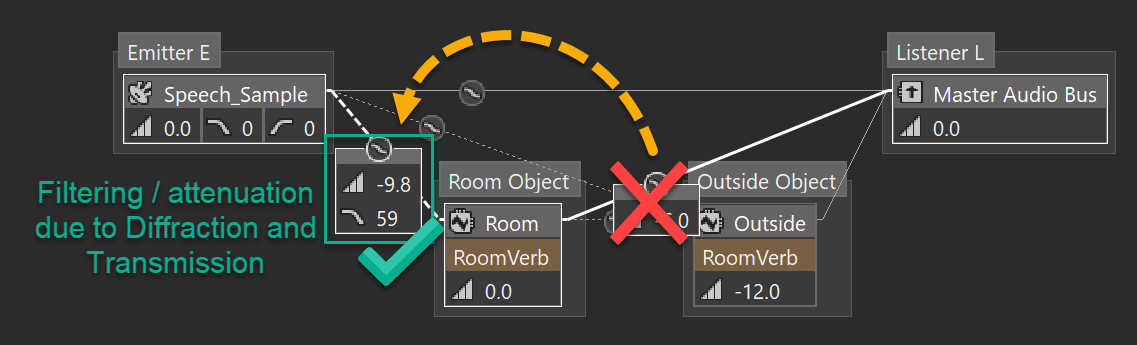
There is, however, a downside to applying diffraction at the input of the Room Bus. It is no longer possible to have a separate diffraction value for the two outputs of the Room. A Room Bus, unless it is the last in the chain (ie. the listener’s room) has two outputs: one direct output to the Listener Game Object, and an auxiliary send for chaining to another room. When diffraction is applied on the input, the signal is pre-filtered and pre-attenuated. Both the direct connection to the Listener Bus and the send to the downstream Room will already be filtered. Compare this to Wwise 2022.1, where diffraction of a Room would only apply to the direct output. Effectively, this means that a sound in an adjacent room can not excite the listener’s room directly. The output is already filtered - it has lost its high frequency energy.
In order to mitigate this downside, and in doing so, accomplish design goal 3, we have added a new connection from the emitter to each adjacent room. Previously, the emitter would only send to the room the emitter is in, and not to adjacent rooms. This new connection does not just come out of nowhere, but indeed it has a physical basis: it represents the sound that propagates directly from the emitter, exciting the adjacent room, but without first bouncing around in the emitter’s room.
Since the emitter now directly excites adjacent rooms, if the listener is inside one of the adjacent rooms, the listener hears the sound with the complete spectrum the correct diffraction value. What is more, sending to adjacent rooms allows us to model the acoustic phenomenon of sound propagating into a room and then back out again (design goal 3). If the emitter and listener are, for example, at the mouth of a cave, the cave is now excited by the nearby sound. Like always, the cave reverb is spatialized in 3D, sounds as if it is coming from the mouth of the cave, and has realistic panning and spread.
Comparing Wwise 2023.1 with Wwise 2022.1
Let’s solidify our understanding by walking through an example, comparing the Integration Demos in Wwise 2022.1 and 2023.1. The Integration Demo is distributed with the Wwise SDK, and you can find it under the Samples section of the Audiokinetic Launcher, if you’d like to follow along. Below, we have a scenario from the “Portal and Geometry Demo”, which I have reconstructed precisely in both versions. The listener is in a room defined as "outside" and is adjacent to the interior room containing the emitter. Two portals connect the two rooms resulting in 3 propagation paths: 1 transmission path through the wall, and two diffraction paths, one for each portal.
Out with the Old: Portals and Geometry in Wwise 2022.1
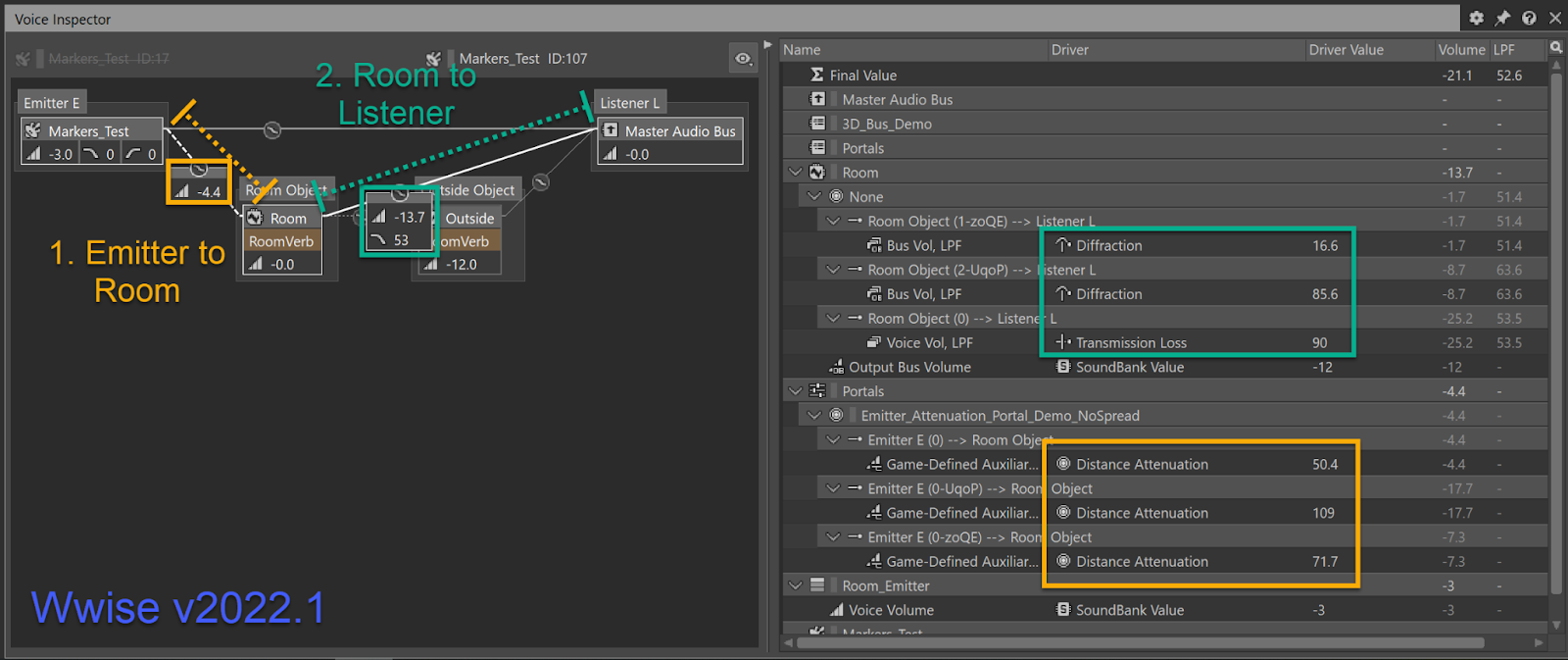
The Voice Inspector has two sides, the voice graph on the pane to the left, and the contribution list to the right. The voice graph reads from left to right, with each node representing an audio buffer that is mixed together, after applying filtering, attenuation, panning/spatialization where appropriate on the connection between nodes on its way to the Master Audio Bus. To understand what happens at each step, we refer to the contribution list on the right, which reads from bottom to top, and shows the volume and LPF values, and how they are derived. In the above screenshot of the Voice Inspector, note the two highlighted connections that form a signal path through the voice graph, starting at the sound and ending at the master bus. Here, “signal path” refers to a sequence of nodes (sounds or busses) in the voice graph, and this is not to be confused with a propagation path, which is what we see in the Game Object 3D Viewer. The propagation path is the path through the virtual world calculated by Wwise Spatial Audio.
A chunk of the complexity in understanding Wwise Spatial Audio revolves around the relationship between propagation paths and signal paths. The signal path is based on the propagation paths - it is composed of the sequence of rooms formed by the shortest path from emitter to listener. They are not, and can not be 1-to-1 because of compromises that have to be made for the sake of practicality and efficiency. Notably, we only want one reverb per room (design goal 4, above), and we cannot have feedback loops in the signal path.
Propagation paths determine the path length and diffraction and transmission coefficients which in turn determine how to filter and attenuate the connections in the voice graph. The propagation paths appear in the contributions list on the right, for their relevant connections.
Note the two highlighted connections:
1) The Emitter-to-Room connection, in yellow.
- This connection represents the energy injected by the source that reverberates inside the room and produces a diffuse field.
- There are three propagation paths shown in the voice inspector on the right, corresponding to the three paths in the Game Object 3D Viewer.
- Distance attenuation is applied here. Since it is part of the wet path, we evaluate the “Auxiliary send volumes (game-defined) curve of the sound. It is very handy to apply distance here, and allows each sound to have a unique “wet” attenuation curve[1].
2) The Room-to-Listener connection, in teal-blue.
- This connection represents the room’s diffuse field, propagating directly to the Listener, possibly through a portal (with diffraction) or through a wall (with transmission loss).
- Again, there are three propagation paths shown in the voice inspector on the right, corresponding to the three paths in the Game Object 3D Viewer.
- In Wwise 2022.1 and before, diffraction and transmission loss were applied on this connection. Notice that a Room bus, unless it is the Listener’s room, has two outputs. One directly to the Listener, and one to the next downstream Room (the “room-to-room” connection). The reason that filtering was applied on this connection was so that we could have unfiltered audio passed to the downstream room on the other output. This was also consistent with the way diffraction (and obstruction) was applied to the direct/dry output of an Emitter, but not to the auxiliary/wet outputs.
- Notice that the diffraction values don’t correspond exactly to the small percentage value shown on the paths in the Game Object 3D Viewer. This is a bit of a subtle point, but has to do with the way we calculate diffraction for the wet path. More on this to come.
In with the New: Portals and Geometry in Wwise 2023.1
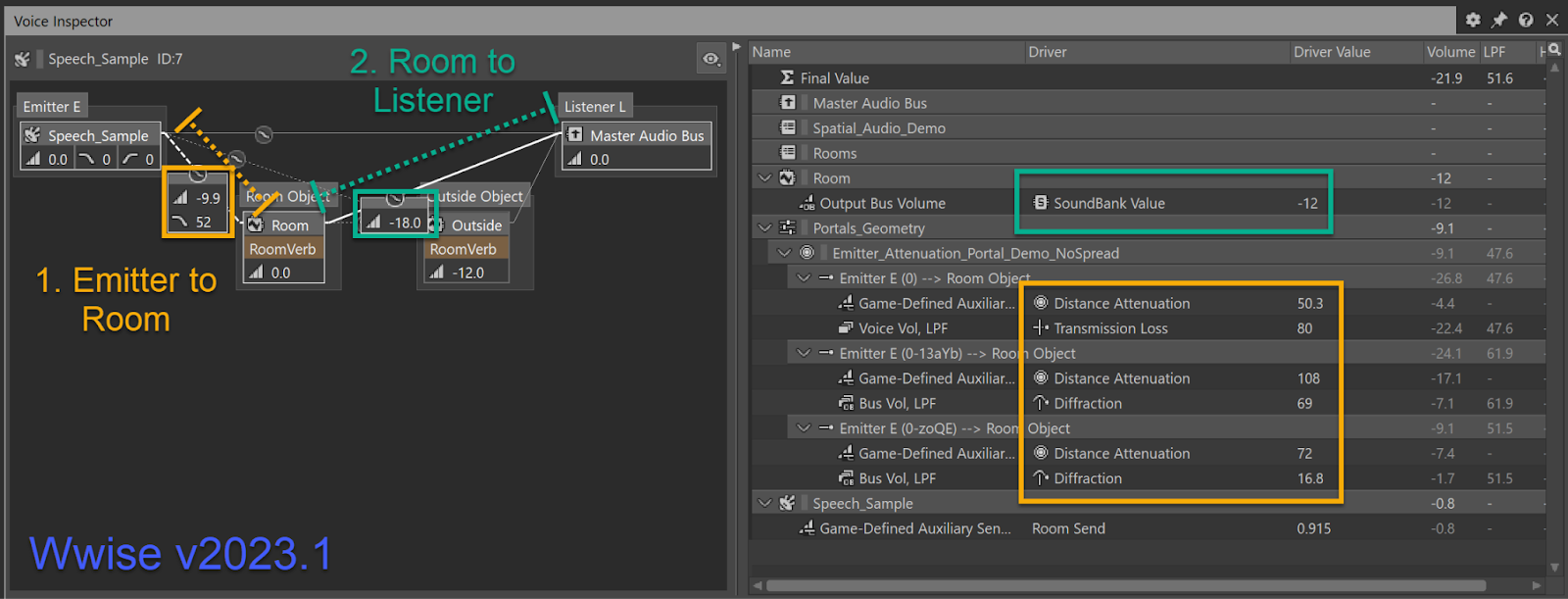
Now look at that! We have diffraction, transmission and distance attenuation all on the first, yellow connection (“emitter to room”). Connection 2 is rather boring now - it only contains the behavioral volume (a way to make a room louder or quieter in the mix by adjusting the bus slider for creative effect).
It is no longer possible to define curves for the Room Bus (design goal 2) - curves on Room Busses are ignored. Now, all curves are in one place, and can be customized per sound (design goal 1)!
Technical Details: Solving a Subtle Volume Issue
Moving transmission and diffraction to the first connection also solves a subtle issue with the way we mix audio in the sound engine. Even though a connection may represent multiple sound paths, we only have a single DSP filter for each connection. If the propagation paths have differing filter values, which is often the case, we use a volume-weighted average to get the final filter value. We then apply a loudness compensation, based on the difference between the desired and actual filter value when we mix the audio together. The resulting mix sounds convincingly as if each propagation path had its own DSP filter. The issue we had in Wwise 2022.1 and before, is that because the distance attenuation is applied on the first connection, and diffraction/transmission filtering on the second, our volume weighted averages are actually incorrect - because each connection doesn’t know what the other is doing. Savvy users might have noticed that their reverb was always a little louder than expected, and even worse, in some circumstances would cut off abruptly when exceeding the end of a distance curve. These reverb volume issues are now resolved, and reverb has never sounded better in Wwise!
Another thing about Attenuation Curves on Room Busses
Here is one last, slightly awkward thing about authoring curves on a Room Bus in Wwise 2022.1. If you were so inclined to define a custom curve for your room, then a small dance had to be performed just-so, in order to get things to work. It was necessary to add a custom attenuation to the Room Bus in Wwise, and then explicitly flatten out the distance-volume curve, because it is the one curve that can not be disabled. Failure to do so would result in distance attenuation being applied to the signal path twice! Life is much easier when you do not have to think about attenuation curves on your Room Busses.
The New Connection: Emitter to Adjacent Room
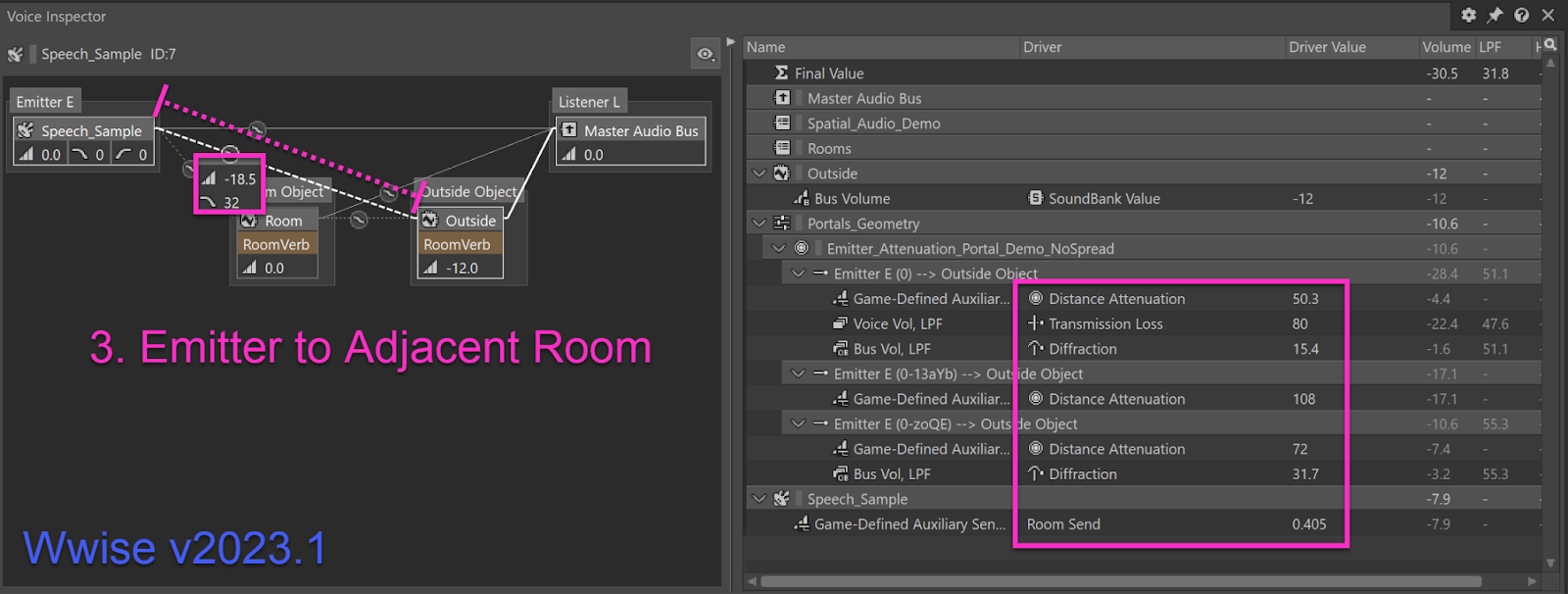
The above screen shot highlights the new connection for 2023.1 - the “emitter to adjacent room” connection. Recall that this connection models sound energy from the emitter that directly excites the adjacent rooms (without first bouncing around in the emitter’s room).
The listener’s room reverb is now excited by a signal chain that is not burdened with the diffraction of the portal. As you can see in the contribution list, it still has diffraction applied, but minimally and strategically. For detailed information about exactly how diffraction is applied to the wet path, refer to the “Wet Path Diffraction” section of the Wwise Spatial Audio documentation, new for Wwise 2023.1.
Perhaps more excitingly, the new connection allows us to model the “cave opening” effect that I mentioned earlier. Give it a try, we think it sounds great!
Of course, we are always concerned about performance, and we do not want to spawn too many reverb busses. Especially if they do not contribute audibly and significantly to the end result. We have added a new setting in AkSpatialAudioInitSettings to limit the number of room sends per emitter. Reducing uMaxEmitterRoomAuxSends to 1 will prevent emitters from sending to adjacent rooms entirely, as was the case in 2022.1. We found that a value of 2 or 3 is a good balance of performance and quality, since louder rooms are always chosen over quieter rooms.
How an Emitter’s Auxiliary Send Values are Calculated
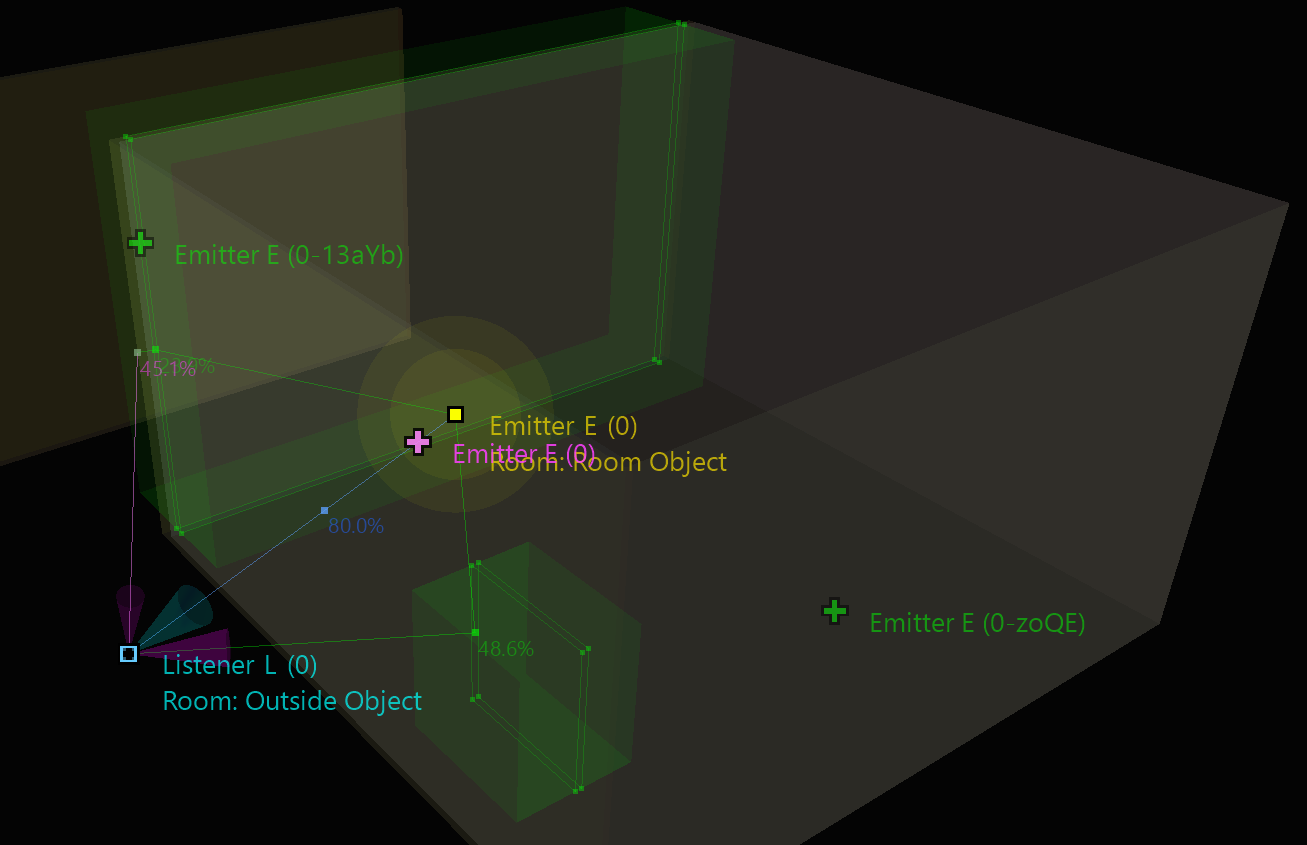
Speaking of louder vs. quieter, I’ll wrap this up with a short explanation of how we settled on the emitter’s Room Send values. Each connection between an Emitter and a Room, either its own Room or an adjacent Room, has a “Room Send” gain which appears at the bottom of the contribution list, and is visible in the above 2023.1 screenshots. A point source emitter, at a fixed distance, has a constant, finite amount of energy to be distributed among its own room and its adjacent rooms. Energy should always be conserved - it should not fluctuate based on position or room, unless specifically dictated for creative purposes using the gain sliders in the authoring tool. At any point in time (and well, space), the squared send values will add up to 1. The amount of energy sent to a neighboring room is determined by the spread value of a portal (technically, it is referred to as the solid angle of the portal, subtended on the emitter), in proportion to the entirety of the sphere around the emitter.
Following is a screenshot of the Game Object 3D Viewer from the top perspective. It is exactly the same Integration Demo scenario presented earlier.
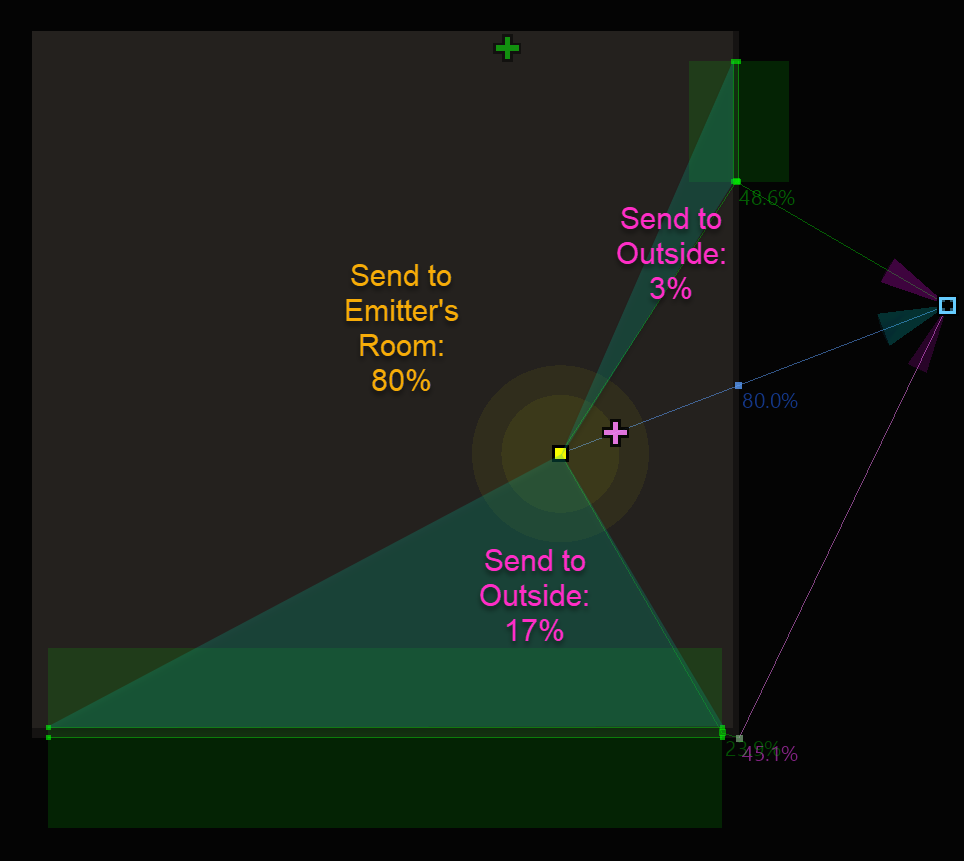
Just like a pie, the sound energy from the emitter is sliced up and divided out between its own room and its neighboring rooms. In the above example, 80% of the energy is “caught” by the emitter’s own Room. This energy is sent to the emitter’s Room reverb bus. The remaining 20% is “lost” to the adjacent rooms, and is sent to the adjacent Rooms’ reverb bus (note that the numbers shown here are approximate and just for demonstration). The proportion of portal surface area to walls determines the balance between room sends. An emitter in a closed off room would send 100% to its own room. Likewise, if there were more portal openings than walls, most of the energy would be “lost” to adjacent rooms.
Wwise 2023.1 is a huge release for Spatial Audio, and the Revised Aux Send Model is really just one part of it. Now go forth and try it out using the Audiokinetic Launcher. If you are not currently working on your own game, the Unreal Demo Game is a great place to get started, or download the Wwise Audio Lab for a rich sandbox for experimentation.
Footnotes
[1] If you were around for the initial release of Rooms and Portals back in 2017, you may have been frustrated because you had to define distance attenuation for each room.

Comments