
Translator's Note:
This is the finale of the three-piece series Loudness Processing Best Practice for Games by the Chinese game audio designer Digimonk, originally published on midifan.com. Closing the series with a post-mortem case study of a released Chinese project, we hope that our effort has helped readers gain a first look at game audio practice in China, as a massive yet under-explored market. Please stay tuned for more in the future.
Translation from Chinese to English by: BEINAN LI, Product Expert, Developer Relations - Greater China at Audiokinetic 
We deal with complex sounds most of the time. In a game, each individual sound contributes to the overall output loudness. We cannot adjust the dynamics and frequency response of any small segment at will, as we do when producing for film or television. Due to such complexity, I found it extremely challenging to explain this topic clearly. Therefore, what I present here is for further discussion with you, the readers! Every experienced designer will have his/her own methodology related to this topic; some can be very personal, others by industry standards. While it can be affordable to handle 10 or 100 assets, balancing the frequency responses and loudness of tens of thousands of assets in games is on a whole different level. This is what sets mass production apart from artistic creation.
Control over asset frequency responses must serve the whole mix, whatever categories of assets at hand, including music and dialogue. Therefore, the first step in the process is to ensure that we make room in terms of loudness and frequency response for other sounds. This is the rule of thumb for loudness control. Take music as an example, the master should have a frequency response of press quality and full dynamics. But the version applied to games or films must leave enough room in the mix; more often than not, it should not use its full bandwidth.
In the current console game domain, the widely adopted RMS loudness references for assets are as follows:
- Music:-16 dB
- Ambience:-16 dB
- Dialogues: -12 dB
- In-game sound effects (SFX): -16 dB
- UI: -16 dB
(The peaks of all the above are below -3 dB, allowing for about ±2 dB deviation)
The usual asset volumes and FMOD volume settings are as follows (Translator's note: All the FMOD references in this article are based on the particular FMOD Designer version used by the game Moonlight Blade):

Under this system, the common workflow is:
1. Set a volume reference for the game. "Volume reference" often means to use the volume of a particular category of sounds as the maximum volume of the entire mix, allowing only a small number of sounds to occasionally overlap or go above this reference. In most cases, the references of choice are dialogues (not including any 'yelling'). Some designers might use music or even UI as volume references. It's according to each project's needs.
2. The assets of the same category, however they might be played back and whatever purposes they might serve, use an RMS close to the aforementioned loudness references. That is, other than dialogues, all assets have an RMS around -16 dB.
3. In the game, the volumes of the sounds are balanced by tweaking the volume and roll-off parameters of the SoundEvents or SoundCues. This is so that you can have a clear idea when a sound is "loud" or "quiet", during balancing.
4. Coloration and frequency responses are often not considered until the mid-to-late stage of a project, when at least 80% of the resources have been integrated into the game. That's when we start polishing and colorizing various assets. The main focus is on the sounds' depths and frequency responses, followed by their sound event volumes.
The idea is to confine individual assets within a relatively consistent volume range, then control and balance the overall output loudness through logic volumes. This "traditional" balancing approach, based on years of mixing experience in the commercial music, film, and TV industries, holds its place for a reason. This approach focuses on static mixing, with some help from dynamic mixing. In principle, balancing through dynamic mixing is not the primary approach, especially during the early-to-mid stages of a project. A direct benefit from the "traditional" approach is that at any production stage, be it assets or events, there will be clear volume metrics for you to judge against. Of course, this approach is still flawed as it requires a high entry fee. The audio designers must be well trained in mixing and must have excellent ears.
This is, in fact, the mainstream approach in console gaming, and has been further developed due to more and more film and TV audio pros entering gaming. The current audio engines also demand that sound designers be equipped with this kind of thought process. The Moonlight Blade (天涯明月刀) project is an interesting case. When I took over the project, the first things I did were to:
1. Quickly browse every category of sound assets. Sometimes I randomly pick assets with a focus in mind. For instance, I group together sounds for character skills and basic body movements, then group yelling and dialogues into another set, and combat music and background music into another. Then I look at the mean and standard deviation of the loudness of the assets within each group.
2. Understand how to set volumes for these sound categories in FMOD and how the volumes computed by the audio engine at run time related to the asset volumes, through experiments with parameter tweaking for both the engine and the assets. It is interesting that every audio engine, even different versions of the same engine, can handle this area quite differently! To me, it is was an extremely brain-burning game to figure out the subtleties :-)
In short, I want to reveal a clear rule among the asset RMS, FMOD event volumes, and the in-game volume. This rule will affect how I balance and polish.
My findings with my project at the time were:
1. With the two basic categories of music, the loudness difference amongst assets was about 10-12 dB. Within the same music category, the average loudness difference was about 10 dB. Within some background music assets, there was at least 10 dB difference at times (between quiet passages and climaxes).
2. The peaks and RMS of dialogues were fairly consistent, but the individual recording sessions were messy. The mic placement, mic amplification, pre-amp, and the actor-to-mic locations differed from session to session. Some dialogues even displayed heavy room reverbs due to inappropriate compression during post-production. The overall RMS variation among character skills and action SFX (regular body movements and skills) was about 9 dB. The high and low frequencies of certain skill sounds were above normal.
3. The mid-ranges of the ambiences were uneven, some having too many low frequencies (based on play tests). The volumes and frequency responses of the ambiences showed little variation, but they needed even smoother variances for better blending with one another.
Because I was given a tight schedule to finish the project, my top priority was batch processing (my first wave of operation), with several goals in mind:
1. Balancing the asset volumes, depths, and frequency responses to make them sound like they were coming from the same batch and abiding by the same standards.
2. Polishing the sound quality, especially of dialogues. The initial assets sounded way too bland.
3. Attenuating above 16 kHz and below 60 Hz for all assets, with slight differences in the amount of attenuation and frequency bands between sound categories.
However, the particular complexity of Moonlight Blade made things more difficult. Under the pressure of our release schedule, following the above procedure line-by-line was apparently impractical. The best bet was to fully understand the current pipeline and the volume processing patterns derived from it, in order to come up with a quick and safe solution. The final volume configuration was as follows:

In this table, I listed the current asset volumes and their volume settings in FMOD, along with the target volumes, for comparison. This comparison proved significant in both the early work on the main release and during the making of the post-release DLCs.
Note:
1. The asset volumes are not absolute but rather mean values based on a lot of random sampling.
2. The target volumes (the Current RMS column) may differ from the final in-game volumes. But normally, the error range is within ±3 dB.
3. All these numbers are retrieved after my first wave of asset RMS cleanup and frequency response balancing (to be discussed shortly), instead of the chaotic raw data. Some resulting delta values in the table were huge and different from common practice. This is mainly because the 3D attenuation with the FMOD version adopted by Moonlight Blade had significant problems. When setting Event Vol = -6 dB for attenuation, the actual in-game volume attenuation was -10 dB. The attenuation had a lot to do with the configuration of SoundMood, too.
4. In the right-most column, i.e., FMOD Vol.Set, we can see that there is not much difference between different layers of sounds. In fact, this is quite unusual. Normally, if asset volume dynamic ranges were small, the dynamics via FMOD volume settings would be greater. The main reason behind this observation is that many events used multi-layers, and used a lot of custom curves for volume computation at run time. The other reason is related to the aforementioned 3D attenuation issue.
For the volume references, I didn't use the usual approach in console gaming and took shortcuts. My approach wasn't perfect, but proved more practical for Moonlight Blade. In the table, you can see the volume layers by paying attention to the color coding of the rows. Simply put, the goal was basically to create distinct layers between the sound categories in terms of coloration, dynamics, and frequency responses.
Before the first wave of asset polishing, I did two things:
1. Batch-processed common assets on a small scale, mainly the music and ambiences of a map, using regular volume settings.
2. Replaced the assets already imported into FMOD with the result of step #1, then adjusted the volumes according to regular settings, and finally tested the results in the game. Actually, I left some important sounds unchanged, such as character skills. This was to reserve significant in-game sounds to compare with the modified ones, so that I got a better idea of the effects of the new settings. This approach was also useful during some later polishing.
Step #1 was further divided into two steps: Batch process assets category by category, then handle special cases one by one. Basic operations were done in Sound Forge:
1. Background music (BGM) was mainly polished and balanced by ultrafunk reverb and EQ to make room for mid-range frequencies. This was because the melody sections are performed with Chinese instruments which focus around the 800-2,000 Hz mid-range. These operations placed the music a bit far back, especially the lead Chinese instruments. To put it simply, I softend all BGMs, moved them to the back of the mix, widened their fields, and made sure their average RMS reached our goals and short-term RMS (climaxes) did not exceed -14 dB. This managed to leave a large space for ambiences.
2. The variations between combat music were big. I picked the assets of greater variance to the rest and attenuated them globally with EQ, reducing the variance they showed in loudness and frequency responses. Then I batch processed the entire group to add a bit of short reverb and cut down on mid-range, low-mid, and even on below 50 Hz with EQ. This left spectral room for the character skills and actions. I maintained the average RMS around the planned level, and attenuated above 12 kHz, with the exception of ambiences to bring out their grainy and airy quality.
3. I attenuated at 16 kHz (heavily) and 12 kHz (slightly) for all character skills to reduce sharpness, and slightly attenuated at 150 and 500 Hz. Then according to the qualitative differences between the skill sets of clans (Translator's note: A clan is a unit in Chinese fantasy games similar to a race in Western games), and rendered the skill sets for each clan with EQ for a maximal differentiation of colors between clans.
4. For ambiences, I batch processed by groups based on the characteristics of the sounds themselves (for example, all daytime valleys as a group) to unify their RMS and frequency responses. Then I used reverb to emphasize their sound fields and depths. I brought winds and rains to the front (using less or no reverb), and pushed everything else to the back of the mix (more reverb and EQ). Some assets were attenuated at 16 kHz, mainly some insect sounds (such as cicadas and crickets) and winds. Even 4 kHz was cut down a lot for these sounds. This was to make it easier for these sounds to blend with other sounds, and also to achieve a softer quality.
5. Dialogues were tough. Traditional EQ and compression couldn't solve the incompatibility between the actor and mic placements during the recording and in-game positioning. I used heavy-coloration plug-ins to render all dialogues so that they share the same qualities. This can brutally reduce the incompatibility, but it was a last resort, albeit a pretty dangerous one. The 12 kHz of dialogues was cut down a lot, aiming for a warmer analog feel. This can also filter out the common performance flaws by Chinese voice actors, such as loud breaths and hisses, which honestly was also related to the choice of mics and mic placement.
Here is the basic batch-processing plug-in chain configuration for the BGM (non-combat music):
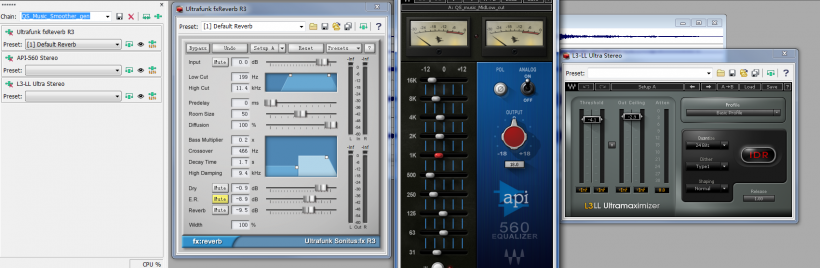
These batch processing and micro treatments have the following details:
1. First of all, these plug-ins all introduce spectral coloration. This is because a) I have a preference to make things sound warmer and b) a general attenuation above 12 kHz will avoid too much high-frequency stacking up in the game, making it more enjoyable. Analog-oriented plug-ins can do an excellent job on high-frequency treatment, making it warm without sounding muffled. In fact, every game project needs a set of coloration plug-ins to give the title a uniform and distinct color. Such a color will become the tone of the game.
2. Not many sounds need to preserve their full bandwidths! Most sounds are attenuated around 500-1,000 Hz, along with below 50-60 Hz. This is because most sounds tend to step onto each other or cause quick accumulation around these two bands (the frequency bands of characters' super skills, explosions, and impacts that cause 'blurry feel' focus between 150 Hz and 600 Hz), squeezing the space available for each individual sound. It's only by taking the initiative to purposely leave out specific space when working on each asset and each asset category that you can achieve a more focused sound while saving space for the rest.
3. Untrafunk Reverb is very special to me. The reverb I needed was a cleaner, less spacious, and less colorized one. The ideal choice would be Sonnox Reverb. But, it was too expensive for me. So, I chose this ancient plug-in that is no longer maintained. Ultrafunk is also one of my favorite plug-in brands, including its Modulator and Delay, which are very useful for mobile games (especially Japanese-style clean sounds). For this project, a reverb was not used to achieve a spatial signature, but to make music blend into other sounds more easily. This is a common practice in the final mix of film and music production. This is also why the reverbs of the music in the post-release soundtracks are usually much drier than the in-game music.
4. Whenever I finished batch processing, I would quickly browse through the assets' RMS status, 'with ears', too. The reason for this: Even if two assets have the same RMS, they may sound like they are placed at different depths in the mix. Unless this is intended, we try to avoid such cases . Also, assets processed in different batches would introduce unpredictable differences in their frequency responses, which I also resolved in this step.
Here is the batch processing configuration for one asset category of 3D ambiences:
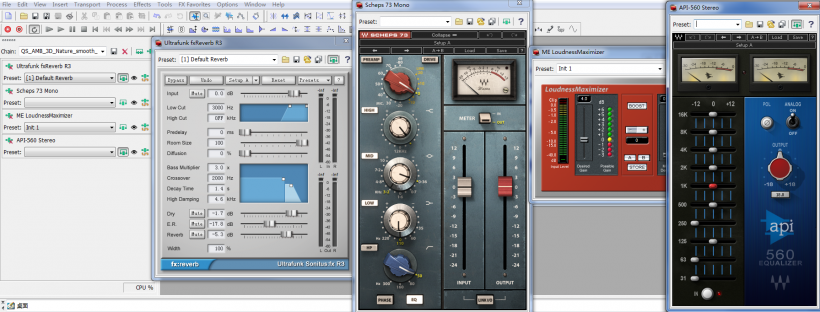
We didn't aim to reach the quality end result for each sound during this stage; nor did we aim to resolve all issues. The sole objective of this step was making sure 90-95% of the assets reach the planned loudness and spectral balance. The result would be that sounds present no particular ups and downs in-game. That's right! Only by this result can you know the perceptual relationship between the so-called core gameplay experience and the audio. If this stage can be called an "area" treatment, then in the next one we get down to the "points", and lots of them. My procedure was to deal with the bigger ones first, then track down the smaller ones. The "big" here is defined by gameplay experience, especially what's related to storytelling and pivots between key scenes.
The macro steps of batch processing:
1. Create all the required plug-in chains in Sound Forge:
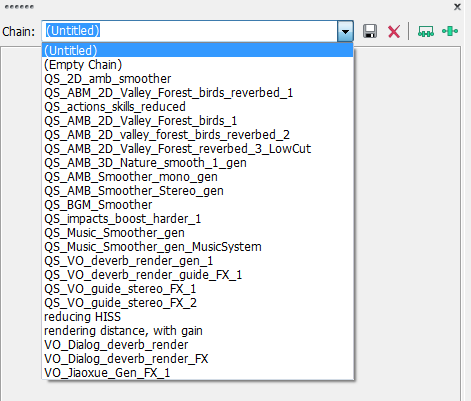
2. Preserve the plug-ins used in each batch, respectively (the files with the BJ extension).
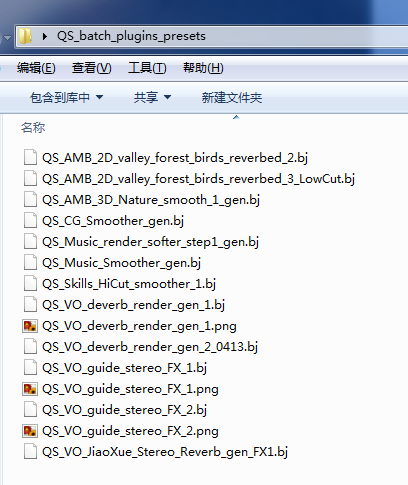
Here are some commonly used batch processing configurations:
- These serve as batch processing presets, written into the Moonlight Blade project documentation and shared with the team. Such an archive is critical for the later incremental content development.
- It's good practice to also preserve the presets within individual plug-ins for your project.
At the same time, the volume differences among sound events are also adjusted by 3 dB steps, such as 0, -3 dB, -6 dB, and -9 dB, according to psychoacoustics. The build will sound as bland as water after this, which is as expected. Some sounds may even sound out of control. This is because previously the event volumes were treated at a fine granularity, which presents a very detailed soundscape; but now the overall balancing flattened them out too much, leading to patterns. "Patterns" are very important because discernible patterns between volume layers will give gamers clearer and a more consistent experience. About this, we can take a close look at American TV dramas. Having lasted as long as 10 seasons, the ratios between volume layers and frequency responses still remain consistent. It's the exact same idea in the case of MMO or mobile games going through various iterations, just as with TV dramas! It is my hope to bring out the layering patterns among different categories of sounds using the multi-tier volume system. The next step would be to go through each category for details, making sure no sound should appear too loud or too quiet, or allocating specific frequency bands for them. The basic approach was still by first doing small-scale sampling and finding good averages, and then batch processing based on the findings. This was to further balance the mix and improve on the layers. Another benefit of this step was to allow for my colleagues to hear potential problems and the real places we needed to work on. I wouldn't start treating individual assets until the end of the global balancing. Actually, as mentioned before, most sounds in FMOD wouldn't get a -9 dB or even -6 dB, which was due to the unknown attenuation algorithms used by the particular FMOD version we used. We would only confirm that starting from -6 dB, we experienced a volume attenuation 'speedy as hell', which was extremely unusual. But it was too difficult to figure out when, given the very short time frame we had.
Before batch-processing each category of sounds, I randomly sampled among each category with large enough datasets, in order to find the good middle ground for plug-in chains and their rendering parameters. This also ensured that the configuration would apply to all incremental content. This work requires experience and burns your brains. The most important work was the QA part: RMS loudness tests combined with listening tests. I must emphasize here that even a Hollywood veteran would need a warm-up before starting a day's work. Such a warmup can be listening to your most familiar music or film soundtrack; it can even involve the work done the day before, to ensure that your listening judgement system stay the same everyday. For some parts of the loudness and spectral balancing, I would even force myself to finish by the end of the day, because those parts would entail more coloration. Consistent listening judgment involves making decisions on frequency response, depth, stereo width, and colors, none of which should be affected by emotional and physical conditions. It takes a long time and a lot of training to develop consistent listening judgement. Let's see a simple example. Find a random high-quality sound library. However big it is, you should find the assets very consistent in basic areas such as their loudnesses, depths, stereo widths, and even their spectral colors. Therefore, good monitoring habits, a stable and clear taste, decent monitoring hardware, and even a good grasp of the plug-ins will all affect your judgment. This is why the industry recommends doing field recording, not just for making a project better but also for effective ear training through the work of post-production and polishing.
When processing the loudness and depth for dialogues, we had a tricky problem, albeit a classic one. We planned to give dialogues different depths depending on situations, which requires pre-rendering the assets. For instance, with the type-B scenarios in the main quest, the dialogues were supposed to fuse with the scene and even have some pre-rendered reverb into them. There were no full-band assets; the narrations and special dialogues emphasized an 'in-your-face' full-band presentation, while the UI voices on mouse clicks would have slightly better presence and a thinner quality, with many frequency bands attenuated and a depth less than 2 meters. The cinematic layers can therefore be delivered in a more dramatic and clearer fashion. However, the file naming convention and categorization of our character dialogues made it impossible for us to quickly extract assets by their categories. Dialogues suffered the most due to the sheer size. We finally had to settle for a global pre-rendering for all the dialogues. This problem happened to action and skill sound effects as well. In the console world, the dialogue assets usually use long names, some even having recording batch indices as part of their names. Localization makes console games more complicated. You can see that the balancing and loudness control for video games is often a systemic project that requires careful planning. You need to consider the file structure, naming, features, and implementation as a whole.
Here are the main plug-ins that I use with Sound Forge:
- Waves All (mainly REQ 4, API560 EQ, API2500 compressor, Schopes 730, and NR)
- Ultrafunk
- Steinberg Masterting Edition
Here are the key stages where asset loudness control happens:
- Music: Master (publishing-ready as standalone material) and in-game assets
- Dialogues: Recording (mic selection and placement, pre-amp selection and configuration, and room acoustics control) and post-production (balancing, noise reduction, and coloration)
- Sound effects: Raw assets, integrated assets (before global balancing), and late assets (the final version after global balancing)
- In-game cinematics: Master (publishing-ready as standalone material) and in-game assets
- Trailers and Promotional songs: Hi-resolution version and Internet version (low-resolution format, co-produced with content providers)
Epilogue
I asked the producers and designers at Skywalker when visiting their studio about loudness. Aside from the aforementioned procedures, they actually approach the different media formats of the same IP (intellectual property) very differently. For example, the theatre version of Star Wars in the United States supports THX, but the home theatre version includes THX, DTS, Dolby AC-3, and Dolby Stereo. On top of these formats, the trailers also include other digital formats, such as Vimeo, YouTube, and QuickTime, or even iPhone and iTunes. They usually recalibrate loudness and dynamics for different playback media, or even use different final mix versions, as opposed to reusing the same mix for post-processing. This is to ensure the best hearing experience is delivered for the different media. The gaming giants like EA and Ubisoft have adopted a similar approach from the film industry. More often, the trailers and cinematics are produced by dedicated teams. It is truly complicated to ensure that loudness and dynamic frequency responses remain consistent throughout team collaborations. Among many things, staff training, workflow, educating about tech standards, and unified toolsets including hardware and software are all very important.
Also, we should prepare documentation on all basic sound categories at the beginning of a project, specifying the asset size, resolution, playback, loading, and integration of each category. For each category, we should clearly document the standard asset frequency responses and dynamics, the recording process, post-production, batch processing, and naming conventions. We should communicate with the production teams and the content providers beyond ideology and requirements, with a decent amount of technical communication, especially during the early stages of a project.
Everything here is just for further discussion and to be used at your discretion. Feel free to correct me if you think I'm wrong about something; it will be greatly appreciated!

Comments
Patrick Bueno
December 27, 2023 at 04:12 pm
What an amazing series with plenty to learn and/or reiterate. Thank you for taking the time to put this together! Off to batch render ... :)