
오디오 프로그래밍 / 게임 오디오 / 사운드 디자인
니콜라 루키치 (NIKOLA LUKIĆ)
우리는 인공지능의 연구개발이 상당한 추진력을 얻고 있는 시대에 살고 있습니다. 그것은 더 이상 공상 과학 소설과 영화의 소재가 아닙니다. 글로벌 인터넷 접근성의 증가, 컴퓨팅 하드웨어의 개선, 기계 학습 및 신경 네트워크가 모두 현재 우리가 처해 있는 상황에 기여했습니다. 이 분야의 업적은 놀랍습니다. AI가 왔고 앞으로도 계속될 것입니다!
현재 AI의 성과는 게임 오디오를 포함한 게임 개발에 긍정적인 영향을 미쳤습니다. 저는 AI의 발전이 어떻게 우리의 팀이 최신 프로젝트의 보이스오버 제작에서 시간과 노력을 절약하는 데 도움이 되었는지에 대한 예를 알려 드리고자 합니다.
Mad Head Games와 Wargaming이 협력하여 개발된 Pagan Online은 슬라브 신화에서 영감을 받은 판타지 세계관을 배경으로 한 빠른 속도의 핵앤슬래시 액션 RPG입니다. 코옵 임무, 사냥, 암살 외에도 50시간 이상의 콘텐츠가 있는 풍부한 캠페인이 있습니다. 이 기사를 쓸 때, 게임은 얼리 엑세스를 진행하고 있으며, Steam과 Wargaming으로 PC에서 플레이할 수 있습니다. 이것은 확실히 지금까지 Mad Head의 가장 야심찬 프로젝트입니다.

PAGAN ONLINE: Kingewitch를 플레이어 캐릭터로 한 캠페인 레벨의 인게임 스크린샷
Mad Head Games의 역사
이 이야기는 저희 스튜디오의 짧은 이력이라도 언급하지 않고는 시작할 수 없겠네요. 매드 헤드 게임즈(Mad Head Games, MHG)는 세르비아에 위치해 있으며, 2011년에 재능 있는 작은 그룹의 친구들에 의해 설립되었습니다. 올해까지 이 스튜디오는 Rite of Passage와 Nevertales와 같은 HOPA(Hidden Object Puzzle Adventure) 타이틀을 만든 것으로 주로 알려졌습니다. 사업이 성장하면서, 점점 더 많은 사람들이 스튜디오에 참여했고, 그들 대부분이 하드코어 게이머들이었기 때문에, 다른 종류의 프로젝트에 대한 욕구가 커졌습니다.
3년보다 더 전부터, 우리는 오늘날 Pagan Online이라고 알려진 프로젝트를 시작했습니다. 이 게임의 개발은 게임과 슬라브적인 전설에 대한 우리의 공통적이고 깊은 열정에 의해 주로 이루어졌습니다. 아무도 언리얼 엔진이나 멀티플레이어 게임 개발 경험이 없었습니다. 오디오 팀을 포함해, 우리 모두는 그 과정에서 배워왔습니다. Pagan Online 이전에는 자체 스크립팅 언어로 전용 게임 엔진을 사용하여 HOPA 및 모바일 게임을 위한 사운드 효과만 생성했습니다.
당사의 모든 사운드 디자이너는 MHG의 풀타임 인하우스 직원이며, 다음과 같은 철학을 공유하고 있습니다.
"소리를 만드는 사람이 게임에서 그것을 구현하는 사람입니다.
이는 당사의 모든 사운드 디자이너는 기본적인 프로그래밍과 소스 제어 원리에 익숙해야 한다는 것을 뜻합니다. 그래서 우리는 새로운 엔진에 빠르게 적응하고 Wwise를 우리의 미들웨어로 사용하는 법을 배울 수 있었습니다.
실용적인 학습에는 물론 장단점이 있습니다; 우리가 모든 것을 '올바른' 방법으로 배우지는 않았을지도 모릅니다. 저는 이것을 미리 말씀드리고 있습니다. 왜냐하면 우리가 어떻게 하기로 선택했는지가 학문적으로 가장 좋은 방법일 수도 있고 아닐 수도 있기 때문입니다. 하지만, 우리는 최선의 의도와 함께 그 과정에서 배웁니다. 우리는 AAA 타이틀 제작에 대한 어떠한 사전 경험도 없었지만, 우리는 우리의 파이프라인의 일부분을 자동화할 필요가 있다는 것을 깨달았습니다. 이것은 우리를 AI 탐구로 이끌었습니다.
상황
HOPA 게임은 스토리 중심적이기 때문에 대화가 많습니다. 영어 원어민인 현지 배우들을 찾기가 어렵기 때문에, 저희 스튜디오는 보이스오버 녹음를 외주하기로 타당한 결정을 내렸습니다. 우리 팀은 게임에서 그것들을 편집하고 실행하기만 하면 되었습니다. Pagan Online의 개발이 시작되었을 때, 우리는 같은 워크플로우를 계속 사용했습니다. 제작 파이프라인에 대해 살펴보겠습니다.
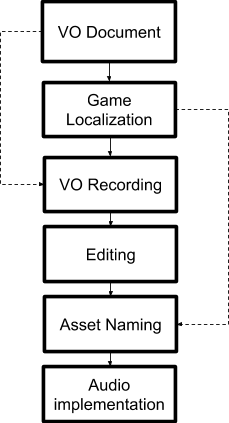
Mad Head Games의 오리지널 보이스오버 제작 파이프라인
위의 그림에서 볼 수 있듯이, 모든 것은 대사의 작성을 담당하는 내러티브 디자이너에서 시작됩니다. 그런 다음 프로그래머는 게임에서 대화 텍스트를 구현합니다. 모든 행을 하나의 로컬라이제이션 파일에 넣고 고유 식별자 문자열을 할당합니다.
ch1_archives:dlg_horrible_11 "Something horrible took Riley!"
HOPA 로컬라이제이션 파일 내의 한 대사 예입니다.
그런 다음 VO 문서가 배우에게 전송됩니다. 각 배우들은 그들의 대사를 단지 쓰인 디렉션대로 녹음합니다. 그들은 우리에게 편집되지 않은, 원본의, 긴 오디오 파일을 보내주죠. 그러면 우리는 파일을 편집하고 최고의 퍼포먼스를 선택한 다음 파일의 이름을 지정합니다. 각 파일은 로컬라이제이션 파일의 식별자를 기준으로 고유한 이름을 사용하여 명명해야 합니다(예: vo_ch1_archives_dlg_horbrible_11.ogg). 즉, 보이스 에디터가 모든 오디오 파일의 이름을 수동으로 지정해야 합니다. 이 프로세스는 느리고 지루하며 시간이 많이 소요됩니다. 우리가 HOPA 게임을 독점적으로 할 때는 큰 문제가 되지 않았지만, 우리가 Pagan Online을 작업하기 시작했을 때, 이 문제가 대두되기 시작했습니다.
이 게임에서 대사 라인의 양은 비교할 수 없을 정도로 큽니다. Wwise와 UE를 사용 중이기 때문에 우리는 오디오 파일의 이름을 짓고, 파일을 임포트 하고, Sound Voice 컨테이너를 만들고, 이벤트를 만들고, 그것들을 적절한 뱅크에 넣고, 마지막으로 UE에서 모든 이벤트를 다시 만들어야 합니다. 또한 이 프로젝트에는 사용자가 읽을 수 있는 글로벌 로컬라이제이션 파일이 없습니다. 대신, 우리는 독자 친화적이지 않은 UE의 DataTables을 많이 사용합니다. 좌절감은 순식간에 치솟았습니다.
우리는 Nuendo의 Rename events from the list라는 기능을 살펴보았습니다. 이와 같은 것이 도움이 될 수 있다고 생각했지만, 오디오 아이템을 목록에 나타나는 순서(게임)에 따라 구성하는 것을 요구합니다. 우리는 보이스오버 녹음을 아웃소싱하고 있기 때문에, 모든 배우를 한 방에 데려와 함께 연기를 할 수 있는 사치는 없습니다. 우리는 또한 그들의 연기를 실시간으로 디렉팅할 능력이 없습니다. 그 결과, 우리는 항상 다른 시간에 다른 배우들로부터 파일을 받고 모든 배우가 대사를 녹음하기 전에는 다양한 케릭터들이 서로 말하는 것을 들을 수 없습니다. 하지만, 우리가 그것을 기다렸다고 해도, 대화 대사가 게임에 등장하기 위해 편집하는 데 걸리는 시간은 엄청날 것입니다. 대신, 우리는 각 배우로부터 파일을 수신할 때 파일 이름을 편집하고 지정할 수 있는 툴을 원했습니다.
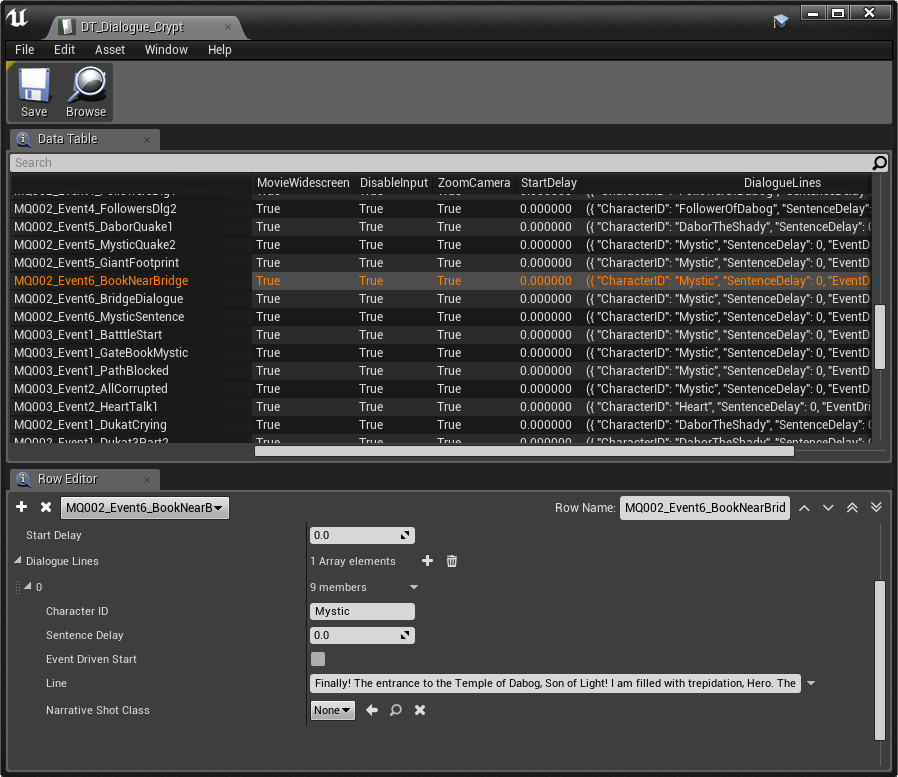
UE 내부의 일반적인 대화 DataTable
우리의 상황을 좀 더 자세히 분석한 후, 저는 보이스오버의 제작과 구현이 더 빠르고 더 효율적이 되기 위해 우리가 해결해야 할 문제들의 목록을 만들었습니다.
-
Datatable 명명 규칙
-
AkEvent 명명 규칙
-
자동화된 이벤트 트리거링
-
자동화된 오디오 파일 이름 지정
-
자동화된 WWise 오디오 임포트 프로세스
-
자동화된 Wwise 이벤트 생성
대부분의 이러한 문제들은 해결하기에 꽤 간단했습니다. 프로그래머는 AkEvent를 문자열별로 검색하는 블루프린트를 Datatable의 대화형 ID를 기반으로 생성했습니다. 우리는 단지 몇 가지 기본적인 명명 규칙에 동의하고 일관적이기만 하면 되었습니다. Wwise 컨테이너 및 이벤트 생성 자동화가 특히 어려우리라 생각했지만, Wwise에서 TSV를 사용하는 것에 대해 알게 되었고, 이 이슈는 처리되었습니다.
자동 오디오 파일 이름 지정 - 솔루션
그러면 오디오 파일의 이름을 수동으로 지정할 때 당신은 실제로 무엇을 하나요? 먼저 오디오를 들은 다음 특정 파일에서 들은 텍스트를 찾아 팀에서 합의한 규칙에 따라 적절한 이름을 지정합니다. 기본적으로 세 가지 프로세스가 있습니다 : 듣기, 검색, 네이밍입니다. 첫 번째 것은 매우 중요합니다. 그냥 듣기만 하는 것은 충분하지 않습니다. 오디오에 인코딩된 메시지를 이해할 수 있는 능력이 있어야 합니다. 메시지는 여러분의 뇌가 소리에서 의미 있는 텍스트로 변환할 수 있는 텍스트입니다. 따라서 이 프로세스를 자동화하려면 녹음된 음성 메시지를 텍스트로 변환할 수 있는 시스템이 필요합니다. 이것은 우리가 AI의 도움을 받을 수 있는 지점입니다.
다행히도, 이런 종류의 시스템은 이미 존재합니다. 그리고 여러분은 그것이 무엇이라고 불리는지 추측할 수 있습니다 : Speech to Text입니다. 음성 인식은 새로운 아이디어는 아니지만, 최근에는 특히 스마트폰의 인기에 힘입어 음성 인식은 정말 괜찮고 접근하기 쉬워졌습니다.
반면에, 목소리는 자연에서 매우 다이내믹합니다. 말하기의 명료함은 사람들이 서로 이야기할 때조차 맞닥뜨리는 문제입니다. 기계는 여전히 사람들처럼 말의 맥락과 억양을 이해할 수 없기 때문에 이 문제에 더 많은 문제를 가지고 있습니다. 영원히 이렇게 되지는 않겠지만, 그때까지 우리는 알고리즘이 이해하고 있는 것을 실제로 말하고 있는 것과 비교할 수 있는 방법이 여전히 필요합니다. 일치하는 양을 평가해야 합니다. 요약하자면, 두 가지 시스템을 구현하는 것이 아이디어였습니다.
- 음성에서 텍스트로
- 대략적인 문자열 비교
이 아이디어가 작동하기 위한 가장 중요한 측면은 사용성입니다. 이는 기술이 존재하는 것만으로는 충분하지 않다는 것을 의미합니다. DAW 내부에서 파일을 편집하는 동안 이를 활용할 수 있는 방법을 찾아야 했습니다.
MHG에서는 유연성과 확장성으로 유명한 REAPER를 사용하고 있습니다. 그래서 이러한 노력을 위한 완벽한 플랫폼이었습니다. REAPER는 스크립팅을 위해 Lua, Eel 및 Python 언어를 지원하며, 앞의 두 언어는 더 빠르고 휴대성이 뛰어난 반면 Python은 방대한 데이터베이스 모듈들을 보유하고 있습니다.
저는 다양한 솔루션을 탐색하기 시작했고 몇 주 동안 테스트와 실패를 겪은 후 프로토타입 솔루션을 개발했습니다. ReaCognition은 대화 파일 이름을 자동으로 지정하기 위해 SpeechRecognition 및 fuzzywuzzy 문자열 매칭을 사용하는 REAPER용 Python 스크립트입니다.
ReaCognition
이 스크립트는 오디오 파일의 선택한 부분을 스캔하고 음성 인식을 적용하는 방식으로 작동합니다. 게임에서 모든 대화 대사가 포함된 특수 데이터베이스와 비교된 텍스트를 받게 됩니다. 스크립트를 실행하기 전에 이 데이터베이스를 준비해야 합니다. 일치하는 내용을 찾으면 이 스크립트는 해당 대화 대사의 ID를 사용하여 오디오 파일의 고유한 이름을 구성합니다.
(새로운) 절차
아래 이미지에서 새로운 대화 제작 파이프라인을 보실 수 있습니다. 프로세스는 거의 동일하지만, ReaCognition의 중요한 추가가 있습니다. 이제 모든 단계에 대해 자세히 설명하여 여러분이 새 부분에 대해 더 잘 이해할 수 있도록 하겠습니다.
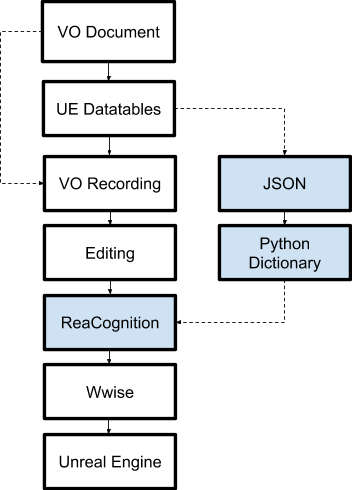
1. 보이스오버 문서
내러티브 디자이너는 게임을 위한 모든 대사를 작성하여 하나의 체계화된 문서에 넣습니다.
2. UE(언리얼 엔진) DataTables
프로그래머는 DataTable을 사용하여 보이스오버 문서의 대사를 게임에 구현합니다.
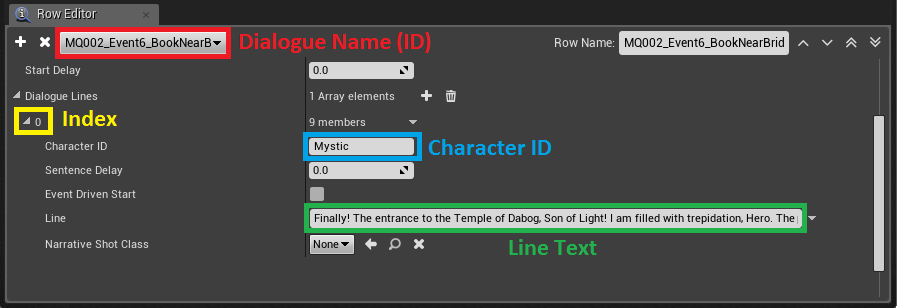
DataTable 내부의 특정 대화 대사 세부 정보
위에서 Crypt 영역에 대한 DataTable 내에서 선택한 한 개의 대화 대사 라인의 내용을 볼 수 있습니다. 데이터는 두 개의 열을 가진 행으로 구성됩니다. 데이터 테이블은 사전 같은 기능을 합니다. 왼쪽은 키, 오른쪽은 값입니다. 모든 대화에는 고유한 이름(ID)이 있으며 여러 대사로 구성됩니다. 각 대사 라인에는 고유한 인덱스와 Character ID가 있습니다. 런타임에 특수 Blueprint(BP_DialogueManager)는 데이터 테이블에서 값을 추출하고 공식을 사용하여 긴 문자열을 생성합니다. 아래에서 AkEvent 문자열을 만드는 공식을 볼 수 있습니다.
FORMULA: DLG_(Area)_(DialogueID)_(Index)_(CharacterID)
Example:
DataTable: Crypt
ID: MQ001DukatAppears
Index: 01
Character: Dukat
Line: Hello there! How can I help you?
AkEvent name: DLG_MQ001DukatAppears_01_Dukat
AkEvent 이름 문자열은 AkEvent를 트리거 하는 데 사용됩니다. 우리는 UE 프로젝트 내에 수백 개의 AkEvent 에셋을 만들 필요가 없도록 이 접근 방식을 사용하기로 결정했습니다. 이 방법으로, Wwise 프로젝트 내에 Event가 존재하고 적절한 대화 뱅크가 로드되었는지 확인하면 되었습니다.
BP_DialogueManager는 텍스트 상자를 생성하고 AkEvent를 트리거합니다.
3. 보이스오버 녹음 및 편집
배우들은 그들의 대사를 녹음하고 우리에게 긴 오디오 파일을 보내줍니다. 보이스오버 편집자는 파일을 편집하고, 최고의 테이크를 선택한 후 교정 및 크리에이티브 프로세싱을 적용합니다.
4. ReaCognition
4.1 대화 데이터베이스 작성
ReaCognition을 사용하기 전에 먼저 ReaCognition 대화 데이터베이스를 생성/업데이트해야 합니다. 이 파일은 특수 Python 사전 파일이며 모든 대화 상자 데이터 테이블의 최신 대화 대사를 포함합니다. 이 파일에서 키는 AkEvents 이름이고 값은 대사 라인 자체입니다. 이 데이터베이스를 만드는 과정은 2단계입니다. 먼저 UE에서 모든 대화 Datatables를 선택하여 JSON 파일로 내보냅니다.
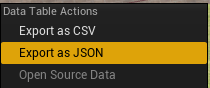
UE 내 DataTables의 컨텍스트 메뉴
그런 다음 REAPER 내부에서, 모든 JSON 파일에서 데이터를 수집하여 하나의 큰 사전에 저장하는 특수한 스크립트를 실행합니다. 이 사전은 AI 인식 텍스트와 비교하는 데 사용됩니다.

성공적인 대화 데이터베이스 생성 후의 콘솔 메시지 출력
4.2 항목 이름 지정
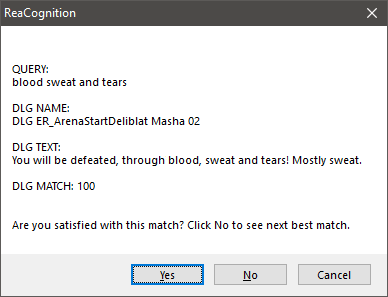
이제 REAPER 내부의 오디오 항목 이름을 지정할 준비가 되었습니다. 보이스 에디터는 항목 또는 항목의 일부를 선택하고(타임 셀렉션 사용) ReaCognition 스크립트를 실행합니다. 몇 초 후 아래 이미지의 메시지와 유사한 메시지 상자가 나타납니다.
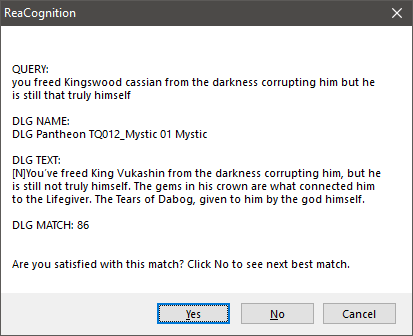
일반적인 ReaCognition 출력 메시지 상자
- QUERY는 AI가 선택한 오디오 항목에서 인식한 텍스트입니다.
- DLG NAME은 찾은 대화 대사의 이름입니다.
- DLG TEXT는 대사 텍스트입니다.
- DLG MATCH는 QUERY와 DLG TEXT 사이의 일치 비율입니다.
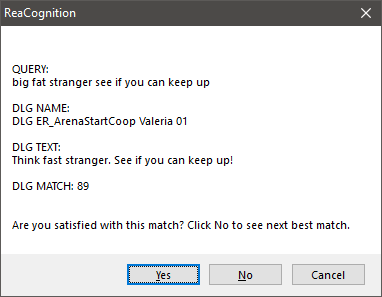
AI가 특정 단어를 오해한 예
위의 예에서 여러분은 몇 개의 단어들이 완전히 오해받고 있다는 것을 분명히 볼 수 있습니다. 다른 단어들이 올바르게 이해되는 한 이것은 문제가 되지 않습니다. 이 스크립트는 항상 쿼리와 가장 가까운 일치 항목을 찾습니다. 대부분의 경우 첫 번째 결과가 찾으려는 결과이지만, 그렇지 않은 경우 '아니요'를 클릭하면 다음 베스트 매치가 표시됩니다.
결과에 만족하면 '예'를 누르면 오디오 항목이 새 이름을 얻게 됩니다.
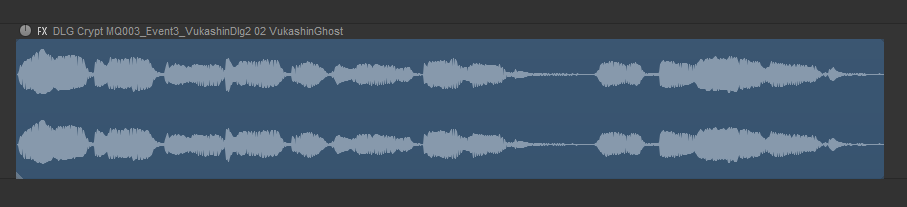
ReaCognition을 사용한 후의 오디오 항목 이름
참고: 이름의 공식 부분 데이터 값 사이에 밑줄 대신 공백이 있음을 알 수 있습니다. 그 이유는 이 글의 뒷부분에서 설명하겠습니다.
ReaCognition을 사용하는 방법에는 두 가지가 있습니다 - 안전한 방법과 빠른 방법.
안전한 방법은 항상 전체 보이스오버 대사를 검색하는 것입니다. 이렇게 하면 최상의 결과를 얻을 수 있지만, 오디오가 길어질수록 결과를 얻는 데 시간이 더 오래 걸립니다.
빠른 방법의 경우 보이스오버 대사에서 가장 잘 인식되고 고유한 부분만 선택하는 것이 빠른 방법입니다. 이 경우 일치량은 전체 대화 데이터베이스에서 선택한 오디오 부분의 고유성에 따라 달라진다는 문제가 있습니다. 현명하게 선택하는 것이 중요합니다. 아래에서는 이 접근법의 예를 볼 수 있습니다.

ReaCognition을 사용하여 보이스오버의 일부분만 스캔
보이스오버 세그먼트만 스캔한 후의 ReaCognition의 출력
수동 ReaCognition
AI가 그야말로 오디오의 내용을 이해하지 못하는 상황이 있습니다. 그런 경우를 위해, 저는 특별한 모드를 만들었습니다. 사용자는 오디오 항목을 선택한 다음 텍스트 상자에 입력하여 쿼리를 수동으로 생성합니다. 구두점 기호를 입력할 필요가 없습니다. 케이싱도 무시되고, 심지어 단어의 순서까지도 섞일 수 있습니다. 유일하게 중요한 점은 여러분이 ReaCognize 하려고 하는 보이스오버에서 충분한 특징적인 단어를 선택하는 것입니다.

쿼리를 수동으로 입력
5. Wwise - 컨테이너 및 이벤트 생성하기
모든 항목의 이름이 올바르게 지정되었다면, 이제 Wwise 프로젝트로 렌더링하고 가져올 때입니다. 렌더링은 REAPER의 유연한 렌더링 엔진을 사용하여 수행됩니다. 저희의 경우, 파일 이름에 $item 와일드카드를 사용하여 선택한 모든 항목을 절대적인 위치에 렌더링 했습니다.
임포팅하는 것은 해결하기에 조금 더 복잡했습니다. 이 프로세스 단계는 TSV 파일을 사용하여 자동화한 것입니다. 여러분이 Wwise에서 이것을 잘 알지 못한다면, 이 시스템은 오디오 파일 경로와 컨테이너 및 이벤트의 미리 정의된 구조가 포함된 텍스트 목록을 사용하여 컨테이너 및 이벤트를 생성하는 시스템입니다. 이것은 매우 강력하고 TSV보다 유일하게 더 강력한 것은 WAAPI라고 말할 수 있습니다. 하지만 제가 ReaCognition을 만들 때, 저는 그것을 알고 있지 않았습니다.
전체 절차는 먼저 모든 오디오 항목을 선택하고 렌더링한 다음 스크립트를 실행하여 TSV 파일을 생성한 후 커맨드 라인을 사용하여 Wwise로 자동으로 가져오는 것입니다.
위의 ReaCognition 출력 예제에서는 오디오 항목의 생성된 이름이 완전히 공백이 없는 것은 아닙니다(예:"DLG MQ001DukatAppes 01 Dukat"). AkEvents의 이름은 밑줄로만 지정해야 하지만 오디오 파일 및 컨테이너에는 이러한 제한이 없습니다. 이 장점을 사용하여 선택한 오디오 항목 이름으로 인코딩된 정보를 기반으로 TSV 파일을 생성했습니다. 공백은 정보를 문법적으로 분석하는 데 사용됩니다. 이름의 각 부분은 특정 컨테이너와 일치합니다.
<WorkUnit> Dialogue
<Actor-Mixer>Dialogue
<Actor-Mixer> Map
<Actor-Mixer> DialogueID
<Sound Voice>Filename
<Sound Voice>Filename
<Sound Voice>Filename
검은색 라인은 절대 경로이고 파란색 라인은 상대 경로입니다(각 오디오 항목에 따라 다름). 이벤트를 만들 때도 동일한 로직이 적용되었지만 띄어쓰기를 밑줄로 교체해야 했습니다.
오디오 카테고리에 있는 대화 WorkUnit 구조 - 자동으로 생성됨
6.언리얼 엔진
마지막 단계는 새로 생성된 Event와 함께 대화 뱅크를 구축하는 것입니다. Blueprint는 게임에 대화 상자가 나타나면 자동으로 오디오를 트리거 합니다.
결론
제가 보이스오버 제작 파이프라인에서 문제가 무엇이었는지 설명하는데 성공했으며, 이를 어떻게 해결했는지에 대해 충분히 설명했기를 바랍니다. 저희 솔루션이 마음에 드시고 여러분의 프로젝트에 무언가 비슷한 일을 하고 싶으시면 언제든지 연락 주십시오. 현재, ReaCognition은 단지 하나의 특정 프로젝트를 위해 만들어진 도구입니다. 하지만 제 계획은 확실히 미래에 그것을 공개적으로 사용할 수 있도록 하는 것입니다. 특히, 그러한 도구가 상당히 필요한 경우에 말이죠.
다시 한번 말씀드리지만, 저는 이 작업 흐름이나 심지어 ReaCognition이 이 문제에 대한 최고의 해결책이라고 주장하지는 않습니다. 하지만 이것이 우리가 처리한 방식입니다. 저는 이것을 게임 오디오 커뮤니티와 공유함으로써 우리 모두가 서로 배울 수 있도록 하고 있습니다. MHG 오디오 팀은 프로세스에 대한 제안과 의견에 열려있습니다. 어쩌면 당신이 우리가 그것을 개선하도록 도와줘서 저희가 ReaCognition을 전혀 사용할 필요가 없을 수도 있죠. 우리 팀은 AAA 게임 오디오 제작 경험이 별로 없어서 뭔가 잘못했을지도 모릅니다. 만약 그렇다면 우리는 확실히 알고 싶습니다.
음성 인식을 사용하는 것은 게임 개발에서 AI의 잠재력을 보여주는 하나의 작은 예일뿐입니다. 저는 최소한 여러분이 게임 개발 산업의 더 밝고 더 흥미로운 미래를 상상하도록 영감을 주었다고 믿고 싶습니다. 가능한 모든 업무가 자동화되고 사람들이 자신들의 창의성만을 사용하는 그런 미래 말입니다. 그런 환경에서, 퀄리티만이 성공의 유일한 요인이 될 것입니다.

댓글